The other day, I read a blog post that was uncharacteristically spot on. It is called McDonald’s Theory. The theory just states that it is easier to start from a bad foundation than from no foundation. The idea is that when a group of coworkers go to lunch, nobody has any idea about where to go. By proposing McDonald’s everybody agrees that is not a possibility, and starts proposing alternatives. Instead of coming up with a first suggestion, they just have to improve on a bad one.
This is extremely applicable in software development. In this post I will go over why that is the case and how I approach development, and some of the tools that makes this a viable choice.

Software is not Bridges
There is all sorts of advice saying that if you try your best, you cannot do anymore; understood that if you give it all you got, it is good enough. That is a bunch of bullshit. If you are a doctor and fails an operation or an engineer who makes a mistake when designing a bridge, bad things happen. For some tasks, the cost of failure in early stages is so high, it is worth a lot of effort to avoid mistakes.
Software is different. Of course, any software you deliver should be good enough for whatever purpose it is intended for, but the cost of changing software during development is miniscule. Some software is so critical (think controller software for nuclear power plants, software for robots going off-world, software for healthcare, etc.) that it is worth a lot of effort to ensure that the final product is super-stable, but this does not mean that it is important that intermediate versions are. And let’s just be honest: most of us don’t write software for nuclear power plants.
Design Saves Productivity
Your program needs a good foundation. That is something that is actually difficult to change after the fact. One of the things happening between Windows 98/ME and Windows 2000/XP was a major architectural change, and the same between Windows XP and Vista/7. The first change happened in the background so few noticed it, but the other change was happening to Microsoft’s major product, causing numerous delays and problems – some of them Microsoft’s fault but mostly just problems arising from incompatibilities. Foundation is a big thing.
Luckily, foundation is well-understood. Unless you are doing something truly revolutionary (and let’s face it: you are not), you can get a design directly off-the-shelf. 90% or more of all applications can easily be written using just one of the standard application frameworks (.NET, Java/Swing, or Java/SWT). They are (more or less) well-thought-out and provides the basic design for your application. They typically force the basic structure and the rest is up to you.

But for the remainder, you should not need to do a lot of thinking yourself. Read and familiarize yourself with basic design patterns if you haven’t already. You don’t need the entire book – focus on the composite pattern, the observer pattern, the model-view-controller pattern, and the visitor pattern. Depending on your application, also the command pattern is useful. That’s it. Read the headlines for the others so you know what is there, but there is no reason to read about most of them in detail.
Design Kills Productivity
This is important. You need the basic design down for you application, but as mentioned, most likely you have to use an application framework which defines the basic design. That means there is no reason to do more at first. You will use model-view-controller (or your program will be crap anyways) and the basic layout of your application framework, and this means you can get coding directly with no prior design effort.
I typically start in one of two ways when coding. Either I start with the user-interface or I start with the model. Both of these are very straight-forward and good for getting going. You can always start with the model, and you can start with the user-interface if it is important.
Starting with the View
Starting with the view is a nice way to get started. It is very easy to do and you ca use either a graphical tool for making the view or making it using code. No matter the way, just make a quick prototype. No reason to make it anything but functional at first – it is easy to adjust it later.
You can make a mockup if you want, but just make 4 lines on a piece of paper. If you start using tools for mocking up, you spend too much time adjusting the exact size, adding pretty icons, etc. Here is a real-life mockup I made last week when I had to make a quick program. Mockup done in one minute, final program done in an hour. Had I started with design and focus groups, I wouldn’t have finished by now. I just needed the basic position of the various elements, and didn’t spend any effort on making the elements resemble anything (didn’t even spend time making my rectangles rectangly). Going from this mockup to an implementation of the GUI was around 15 minutes.
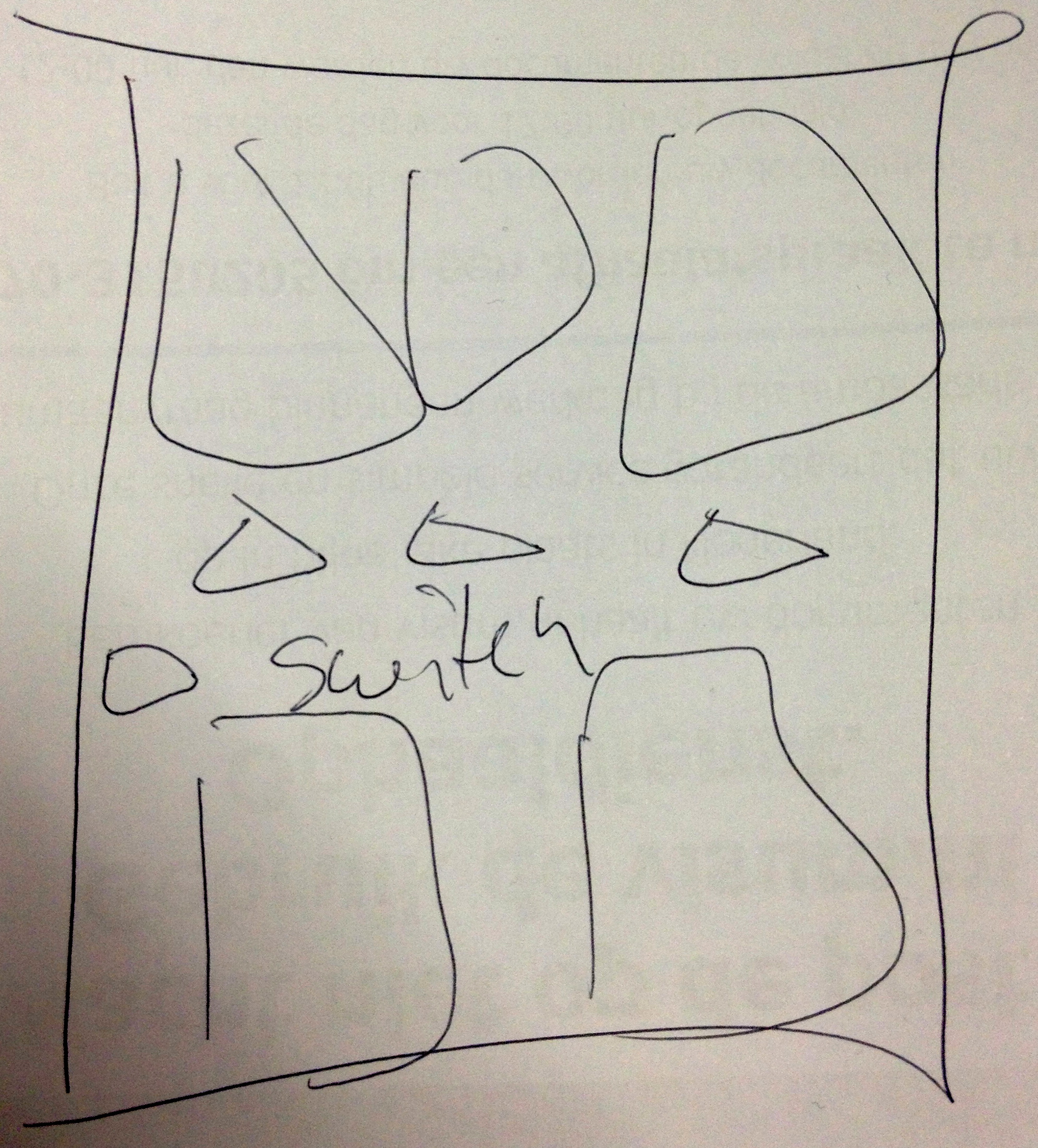
If you start with the view, you are forced to think about the flow of the program and it becomes evident what functionality will be needed: enough that clicking on all your wonderful widgets does something, and the next steps become nearly obvious.
Starting with the Model
Starting with the model is also way to think. If the program is less graphical, this is definitely the way to go. The model represents the real-world counterpart to what your program is doing. If it’s a drawing program, it represents drawings, if it’s a compiler, it represents programs, and so on. Typically making your model is trivial in theory; you want to make a program, hence you have an idea of what the program will work with.
Many people likes to start their model development by drawing UML charts. That is very rarely necessary. UML is fine if the model is a group effort and nobody understands all the requirements, e.g., if a group of stakeholders needs to share a model but has different and maybe conflicting requirements. The difficulty of model development is not the basic structure (for which UML is good), but the details. Spending time making the details with UML is a waste of time, because you may just as well implement it and have an automatic tool extract the UML afterwards.
Making a model is easy. Start with the basic classes you know you need, and add more as you need them. You probably need the composite design pattern here, so start with the composite and add a couple sample elements. It is easy to add more later when you need them, so there is no need to think of everything at first. New requirements become obvious as you move on and can easily be implemented then.
Making the model allows you to make a lot of code in little time. You may want to use a framework like EMF (Eclipse Modeling Framework), but most of the time you don’t need that – writing getters and setters is extremely easy and is often tool-supported anyway, as here in Eclipse:

Ignore “Common Sense”
In software there is a bunch of common wisdom that everybody agrees you should do (but few actually does). This includes unit testing, documentation, and comments. For the most part, don’t waste your time doing so.
Don’t Use Unit Tests
This is against common wisdom, I know, but writing unit tests is often a waste of time. Things that are easy to unit test are trivial to write (so writing tests will find no errors), and things that need tests are hard to unit test.
 It is trivial to make an object model with all the aggregations you want. It is also easy to write tests for that. So easy in fact, that there are tools for automatically generating such tests. If you use such tools, unit tests may be ok, but ask yourself: how many ways are there to write a getter method? Sure, if the setter tests some preconditions, you may want to test that, but is it really so important to test whether “if (parameter == null) …” works? Spend your effort where it matters.
It is trivial to make an object model with all the aggregations you want. It is also easy to write tests for that. So easy in fact, that there are tools for automatically generating such tests. If you use such tools, unit tests may be ok, but ask yourself: how many ways are there to write a getter method? Sure, if the setter tests some preconditions, you may want to test that, but is it really so important to test whether “if (parameter == null) …” works? Spend your effort where it matters.
Things that are complicated are things like consistency of data-structures, correctness of complex algorithms and synchronization. Those are very difficult to test using unit tests and need to be tested using integration tests or stress tests. Synchronization may even need to be checked using model-checking techniques. In principle you could write stubs for all your classes, set up complicated unit tests and find some errors. For highly critical software that may be a viable option, but for most software you just won’t find sufficient amount of errors and not worth the effort.
Testing is about finding errors, not proving absence of errors. Successful testing finds the most errors with the least effort, so approaches that find many errors with little effort should be preferred over approaches that find few errors or require a lot of effort. A simple to make test is one that just starts your program, loads a predefined document, and saves it under a new name. Then do the same with the new file, and compare the two generated files (don’t compare with the original file if it is ok for the format to change). You will exercise a lot of your program, and this test will find tons of errors with virtually no effort.
Don’t Write Comments and Documentation
Most comments are useless. If a line of code says “a = b * 2” there is no comment you can write that conveys that better than the code. If a computation is more complicated, why not move it to a separate method with a useful name – even though the hidden computation may be complex, the assignment “price = computeMortgage(amount, interest, time)” is still readily understandable.
The problem with comments is that they take time to write and the compiler does not check that they are up-to-date. By writing comments that the compiler checks, you get more readable code that is guaranteed to be up-to-date. That is the idea of self-documenting code.
Comments take time to write and maintain. If they just document the trivial parts, they are useless. If they actually document the difficult parts, they take a lot of time to write and maintain. Therefore, avoiding comments whenever possible is good.
That does not mean that you should avoid making your code readable, just that making the code self-explanatory is a better way to go about it. This for example means using symbolic constants instead of constant values (“retailPrice = purchasePrice * 1.19 * 1.25” is less readable than “retailPrice = purchasePrice * VAT * PROFIT_MARGIN”).
Self-documenting code also means moving code to methods. Modern compilers are smart, so adding methods impose no overhead. There is no shame to having methods of just 2-3 lines. Or even one line if it makes the code more readable. This has the added advantage that it is easier to reuse the code or even move the code around.
One thing that’s often documented is preconditions (assumptions) and post-conditions. This to the point that there are formal languages for describing these. Stay away from that, because they also change and wrong documentation – especially important documentation like this – is worse than none. Instead, write assert statements testing all pre- and post-conditions. These are just as readable as any other way of stating the same, they are checked by the compiler at compile time, and are checked by the running program during testing (and removed for production). The assertions will be checked using a simple load/save test as described above, and will reveal many problems.
Using all these paradigms, you don’t really have to write any documentation that will change; just state for complex algorithms what the idea is and the remainder is nice and readable.

Refactor
This is the big one. This is why early design decisions matter less. Refactoring is changing the code around without changing the behavior. Read this book from one end to the other and make sure you understand everything (except for the whole must have unit tests part, because that’s old-fashioned bullshit).
Refactoring is systematic rewriting patterns that improves code readability. One refactoring is extracting a piece of code to a method, another is moving a method to another class. It’s all very simple tasks that can improve reusability and cleanliness.
The refactoring book goes on about how you need unit tests to do refactoring, but I do not believe that to be true anymore. The reason the book advocates this is because at the time, there were no automatic tools to do refactoring. Today, all modern IDEs have at least some refactorings built in. They are guaranteed to be correct ((Ha!)), i.e., if the code worked before, it will work afterwards.
Make Code More Understandable
This is the refactoring menu from Eclipse. We see that we can extract an expression to a method, and create a local variable or a constant from an expression. The three examples I gave for making code self-documenting. We can effortlessly move and rename classes (and all references to them).
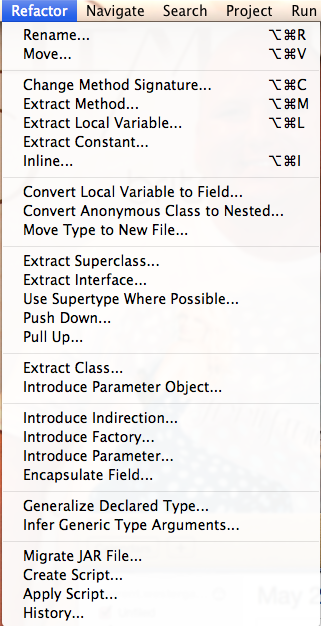
Those are all relatively simple code changes useful for making local changes to make unreadable code self-documenting. Moving down the menu, we can also extract super classes and move methods between super- and sub-classes. This allows us a lot of flexibility when moving code around (moving a method to a super-class makes it available to all sub-classes for reuse automatically).
Don’t Plan for the Future
We also see that we have refactorings for introducing certain design patterns in our code. This means that we do not need to support them from the beginning.
When you do design, you tend to plan for scenarios that may or may not occur in the future. Here’s the thing: most of the things you plan for will never happen. This means that you introduce generality that is never needed. This generality makes your code more complex and harder to maintain. For example, introducing factories is great when you have more of them. If you only ever have one factory, it will make your code more verbose (to read, write and understand) without any benefit (except maybe a slight slow-down on runtime, which is a pretty sucky advantage). A factory is great if you need multiple implementations of the same thing (multiple platforms, alternative implementations of data-structures, etc), but when you don’t they just complicate things. And refactoring can introduce them for you almost for free, so don’t bother with them until you need them.
Instead, write code that does what you need now. It is often simpler and allows you to do stuff instead of planning to do stuff. In the ProM project, we use a different look for widgets than the default Swing look. This is implemented by subclassing and altering existing widgets rather than correctly using PLAF. This alteration takes place partly centrally, and partyly everywhere in the code (when the central solution didn’t suffice). I needed some widgets not already available, but instead of rewriting everything to use PLAF, I continued using the distributed and “wrong” approach. This allowed me to get results. I then discovered I needed similar widgets for different projects. Some I copied around, but when I started making changes in multiple places, I extracted all of these widgets using refactoring until I had a library that was reusable for me. Others started using this library, extending and expanding it. Fixing bugs and adding features. Now, we have a library that is used by the code of 10-15 people. It is still not written in the optimal way, but we have a consistent look and most importantly a common ground. This means that in the futureTM we can introduce a real PLAF and only change one place (the library) to introduce it everywhere, instead of having to make the change in the code of 10-15 people. Thus, we are in the process of introducing a rather fundamental change, but in a way that never broke any code, always improved the code, and always improved the end-user experience.
Never Rewrite
Related to not planning for the future, is sticking with your options. Never rewrite. While it may seem like a breath of fresh air to throw out an old, overworked, and complicated foundation, the new one will be worse than what was there. This happens for two reasons: the existing code base has been tested for a long time – by switching to a new code-base, you throw all that testing away. Second, the new, improved code will be nice until you reach 80%-90% of the functionality of the old one. Then it will get complicated, because the old code base was complicated because it needed to be.
I have burned my fingers on this twice. Once was my fault, the other not and I didn’t really feel the effect; if you get burned once, you’ll never do this again. We had this program called Design/CPN; it did its job, but had some definite problems. One was that it would not run on Windows and another that the GUI editor had been lost and could not be retrieved, so GUI alterations were always hit-and-miss. It was decided to reimplement the tool (at first as a technology demo, but as time progressed to replace the tool). This new tool was CPN Tools. This set back the tool for more than 5 years. The tool was known as extremely buggy for 5 years (compared to the old tool), lacking in features (for 8 years), and still there are features, 15 years later, that the old tool could do that its replacement cannot. There are of course also advantages – now it runs on Windows, the new tool has killer features that makes it better, and is overall much more user-friendly. But imagine what we could have achieved by small, controlled modifications to the old tool in the 5-8 years we spent catching up?
At some point I got so fed up with CPN Tools, I decided to make a rewrite in Java called the BRITNeY Suite. At first it was a technology demo that displayed that replicating the look and feel was indeed possible, as this was one of the major reasons for not making the rewrite. I also had much cleaner code, one of my major reasons for switching, and a far superior pluggable architecture. On the other hand, there were dozens of missing features, look-and-feel issues, etc., that I did not address because they would be in the 10%-20% that were difficult to implement. While the CPN Tools code was bad before my rewrite, at the same time refactoring of the original code was started. The resulting code is still not the best, but it is far better than before, and I was totally wrong in making a rewrite.
CPN Tools currently has one huge problem. It is written in the language Beta, which is not very well-known to say the least, and which does not really support modern platforms (parts of the program runs very badly on Linux to the point that Linux support has been dropped, and there is no hope for a Mac OS X native version ever). It is tempting to make a rewrite, but at least I learned not to attempt that from the BRITNeY Suite. In the end, I abandoned the feature cloning in the BRITNeY Suite, and instead focused on extending the features using the BRITNeY Suite as an external program cooperating with CPN Tools to add new features, developing techniques that were subsequently used in another tool (ASAP), and is now also the foundation of one of the new features of CPN Tools, simulator extensions, which makes it possible to add new native functionality using Java.
Releasing Code
One of the most difficult things (aside from licking your own elbow) is releasing your program. Version 1 is hard to get out because now other people can judge your work (and you go from development to maintenance or maintenance/development). Of course, if you have a single customer or a very strict deadline it becomes easier, but it is still a mental hurdle.
 There are basically two ways to release software: “release on date X” or “release with feature set Y.” One has a fixed data set for release and one requires a certain set of features for release. A very important thing is to never combine these! Combining means you get the worst of both worlds: the release date will slip because features are not done, and features will suck because the release date is approaching.
There are basically two ways to release software: “release on date X” or “release with feature set Y.” One has a fixed data set for release and one requires a certain set of features for release. A very important thing is to never combine these! Combining means you get the worst of both worlds: the release date will slip because features are not done, and features will suck because the release date is approaching.
I prefer releasing on a specific date. Then I look critically at available features and remember to the old adage “kill your darlings,” meaning that even if you are in love with a feature, if it doesn’t work, it doesn’t go in. The code still remains, it is just not accessible. That way, I don’t break anything that wasn’t broken during testing.
Releasing by feature is also possible, but then you need to define features very precisely beforehand. Otherwise, features have a tendency to slip – it can always be better, and you end up with the next Duke Nukem Forever: taking forever to release something that cannot live up to expectations and is frankly worse than anything forced to get released. Steve Jobs said: “Release is a feature. Your product has to have it.” This is important. You can always improve your program, fix bugs, etc., but at some point you have to release. Perfect is the enemy of good, and if you continuously strive for perfect, you never get something good.
Maintenance
Maintenance in my view comprises three phases: major refactoring, new implementation, and testing/bug-fixing. They need to be in this order, though you can skip any but the last one. Continuously during development, we perform minor refactorings to improve legibility. It is for example useful to do refactoring if you take over a piece of code and need to understand it – by refactoring it, you are forced to read and understand it (but in smaller pieces), and as an added bonus, you make it easier for the next person who needs to read it.
 Major refactorings should never be made just before a release because event though they shouldn’t be able to, they may break other code. Major refactorings are about fundamental changes (such as switching from custom widgets to PLAF in ProM, or overhauling the central data-structures and introducing, for example, a generalized visitor). Major refactorings serve to improve the code (which typically deteriorates during bug-fixing and final implementation before a dead-line) and to facilitate the next step, new implementation.
Major refactorings should never be made just before a release because event though they shouldn’t be able to, they may break other code. Major refactorings are about fundamental changes (such as switching from custom widgets to PLAF in ProM, or overhauling the central data-structures and introducing, for example, a generalized visitor). Major refactorings serve to improve the code (which typically deteriorates during bug-fixing and final implementation before a dead-line) and to facilitate the next step, new implementation.
New implementation is about adding functionality. One such example is adding simulator extensions to ProM. This required some refactoring of existing code and adding a ton of new code.
Bug-fixing and testing is obvious. We need to have integration tests, stress tests, and fix bugs found. We should no longer add (major) features, but are allowed to continue refactoring. Around this time, we decide which features go in. If they are buggy late in the development cycle, it is better to hide them and include them in a later patch. You need something for version 2.1 anyway.
Summary
The big point to take away is that software development is easy. It is cheap to make changes. Even after release you can continue making changes to the original design. A dirty secret is that while design may be a nice activity, the end-user is never going to see it, so it is better to spend the time on something the end-user benefits from. Design is a feel-good activity because it allows you pretend to do work, while all you do is draw pretty pictures. Much design is very easy, and the devil is in the details. So why not dive in directly and make things work?
Many traditional disciplines, like testing and documentation, are also feel-good activities, because they allow you to pretend to work, but you don’t produce anything of value to the end-user. Testing is not about code coverage, but about finding bugs, and if you measure code coverage and do unit tests, you are going to do well on paper, but the end result is close to worthless. Documentation becomes out of date, and the easiest documentation to write is the useless one. There is no reason to document what is in the code, only the things that cannot be gleaned from the code. Instead make your code easy to read.
Refactoring as a constant activity will improve your code. It will make documentation superfluous. It will make thinking too much about the initial design superfluous, because you can change your mind later. Design for the simplest that works now – “less is more((Except when it comes to alcohol or bacon, in which case more is more.))” and “worse is better.”
Another point is that there is no idea to familiarize yourself with all kinds of complicated development strategies. While it can be useful to know them, often they are just there to avoid doing work. Even the low-overhead ones like Extreme Programming and SCRUM are mostly present so bad programmers can pretend to be productive without writing code. Whenever somebody talks enthusiastically about SCRUM or XP or whatever is popular, ask them how much using those techniques have improved their code: how much did they write before and how much do they write now.
So, don’t over-think it, just get started; you’ll have a BigMac within a day, and be able to turn it into a juicy steak in one tenth of the time of making the steak from scratch. Which is where the McDonald’s analogy breaks down.

Nice post Michael! Thanks for sharing your years of experience 🙂
Glad you like it 🙂
Nice thought out post.
You can unfortunately not disqualify unit testing in all development, but I agree that most basic unit testing is useless.
If you are not working on a crypto library functionesque feature I have yet to find a situation where it was of primary concern to test every single small module behavior.
You can probably apply this thought to brewing beer (“cider”) as well… I will let you know the result.
Спасибо. Doing crypto in a bank is of course closer to control software for a nuclear plant,mane not really the kind of development I’m targeting in the post. I would like to taste a unit-tested beer/cider, though 😉