So, here’s an interesting Java issue I came about last week.
Java EE supports annotating methods using an @Transactional annotation. If you’re familiar with it, it’s similar to the synchronized keyword except on the database level. It also is if you’re not familiar with synchronized.
Transactional supports setting how transactions should be picked up – in particular, you can use REQUIRED to have a transaction created if one doesn’t exist or reuse the existing one if it does. You can also use MANDATORY to reuse an existing transaction if existing or fail if not. REQUIRED closest matches what synchronized normally does.
There’s a couple other types, but of most interest is the REQUIRES_NEW parameter, which indicates that regardless of whether there was a transaction already, a new one must be created and the method executed in its own context. This setting allows us to make a small utility method which is executed in its own isolation level. That will be useful for, e.g., audit logging, where you want your audit log updated regardless of whether the surrounding request succeeds or fails (or, a rollback of the outer transaction should not cause a rollback of the write to the audit log so it should have its own isolation level).
We ran into an issue with this. The problem is that on a real application server, you use a connection pool for your database connections, and often times, this is configured with a fixed set of connections so you don’t crash your application or database if somebody sends off a million requests.
 The most basic problem in concurrency theory is that of the dining philosophers. 5 (arbitrary number) philosophers sit around a round table. Between the philosophers are chopsticks; one between each pair for a total of 5 (or, in general, as many as there are philosophers). Each philosopher needs two chopsticks to eat, so they need to take both the left and right one. For each side they compete with their neighbors for the shared resource. As soon as a philosopher has one chopstick, they refuse to let it go for fear that their neighbor will take it (I’ve got my eye on you, Socrates!). If a philosopher cannot grab both chopsticks, they will instead just sit and think. Once they have both, they will partake in boring earthly rituals (eating).
The most basic problem in concurrency theory is that of the dining philosophers. 5 (arbitrary number) philosophers sit around a round table. Between the philosophers are chopsticks; one between each pair for a total of 5 (or, in general, as many as there are philosophers). Each philosopher needs two chopsticks to eat, so they need to take both the left and right one. For each side they compete with their neighbors for the shared resource. As soon as a philosopher has one chopstick, they refuse to let it go for fear that their neighbor will take it (I’ve got my eye on you, Socrates!). If a philosopher cannot grab both chopsticks, they will instead just sit and think. Once they have both, they will partake in boring earthly rituals (eating).
The interesting case is what happens if all philosophers pick up the left chopstick. All philosophers will have exactly one chopstick and will be waiting for their right chopstick. The system is in a deadlock and cannot proceed: all philosophers refuse to put down their one acquired chopstick, and cannot get the second one they need to proceed. The same can happen if they all pick up the right one.
Now, what do these things have in common? Consider the dining philosophers problem, but instead of doling out one chopstick between everybody, we put all 5 chopsticks in a pile in the middle of the table. Now, all chopsticks are shared, so each philosopher just has to pick two chopsticks from the table, first one then the other, in order to eat. All the resources are shared so the system can proceed much more efficiently. Therefore, the philosophers only get 3 chopsticks. As Bill Gates of failed Seattle start-up Traf-O-Data famously said, 3 chopsticks ought to be enough for anybody.
The interesting thing is that this is identical to our program: each thread needs two database connections to operate: one for their main task and one for the auxiliary task with @Transactional(REQUIRES_NEW) (at least with our database implementation we need an extra database connection to handle nested transactions). The application has a limited supply of database connections. Now, the question, of course, is, does this variant of the dining philosophers potentially cause a deadlock? We discovered in practice that it does.
We did some analysis and came to the conclusion that this indeed was the issue. We had to supply a list of recommendations for how to solve the issue. For that reason, we essentially had to consider other variants of the dining philosophers problem. To make it easier to explain the problem and also to make sure that the proposed solution was indeed sound, I decided to make some colored Petri net models of the problem and solutions.
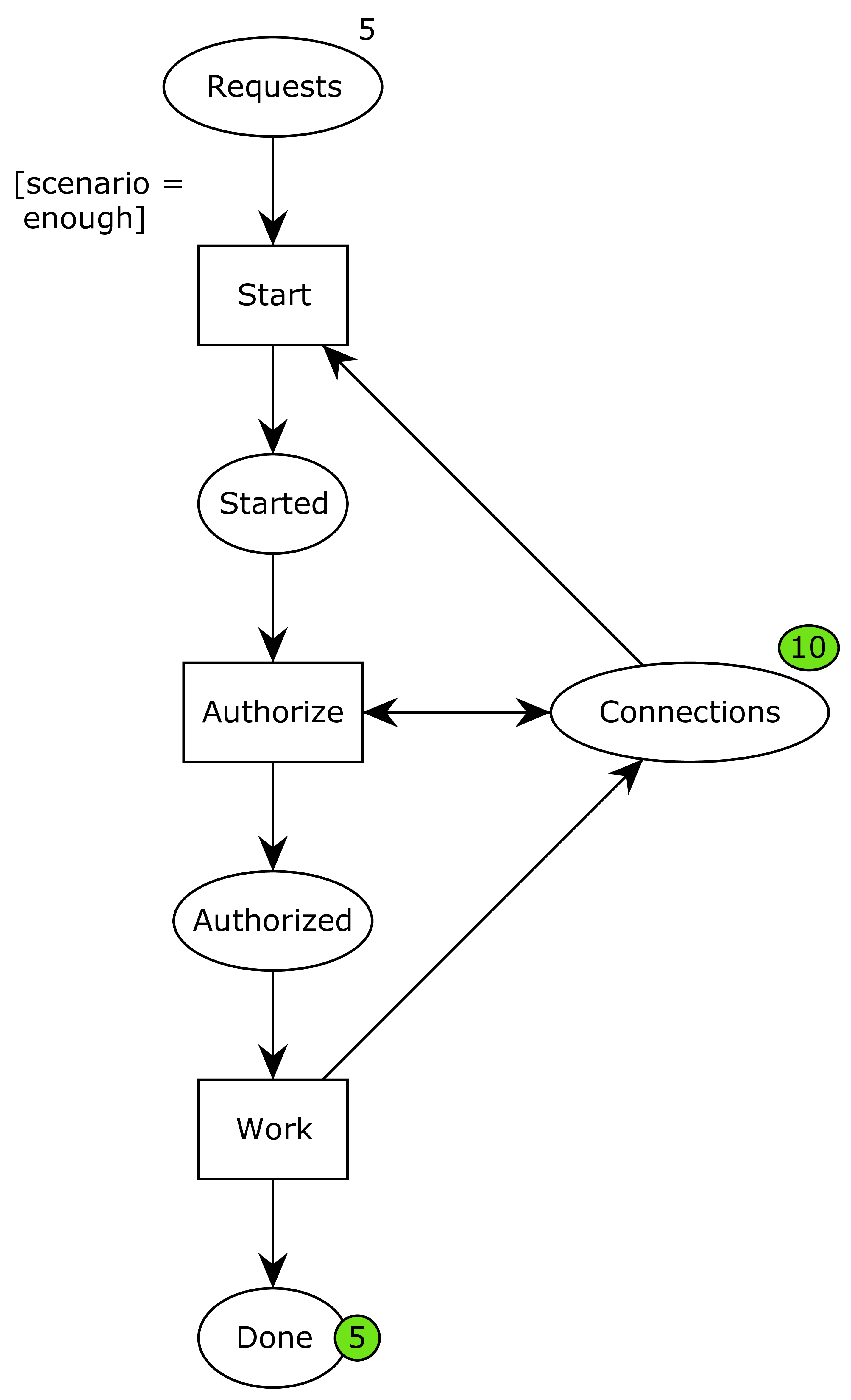
First, I modeled the original problem:
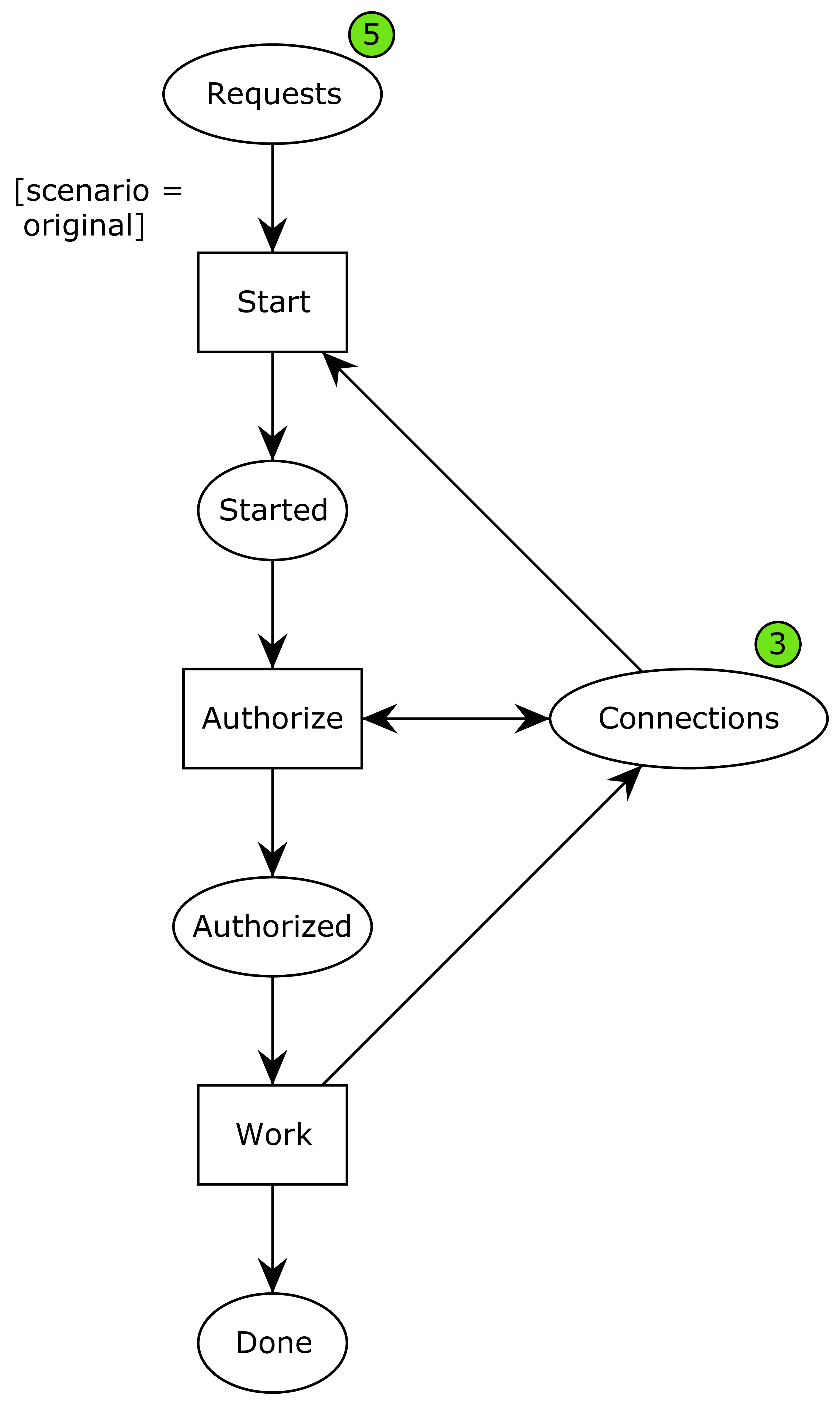
Here, ellipses represent data or resources and rectangles actions. We initially have 5 requests and 3 connections. Once the requests start processing, they consume a connection and are then started. They then start an authorization phase, which is where the nested transaction comes in. In order to do this phase, another connection is required, but the resource is put back immediately afterwards, and the process moves to the authorized state. Finally, they can perform the work, hand back the final connection, and continue to the done phase.
Here is the system after two processes have started working:
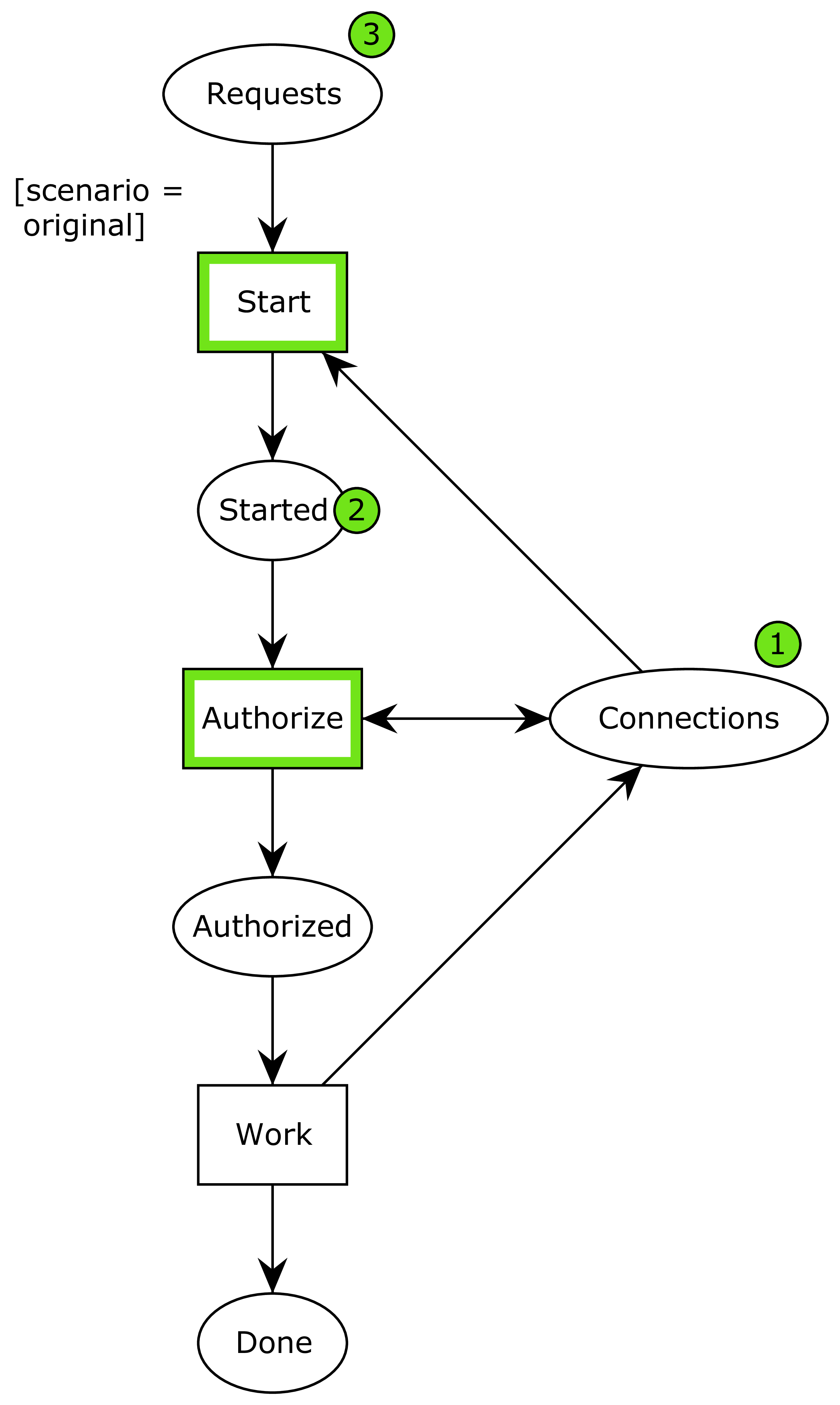
It is possible for another process to start or one of the already started processes can complete the authorization phase. If we let another process start, we get to this state:
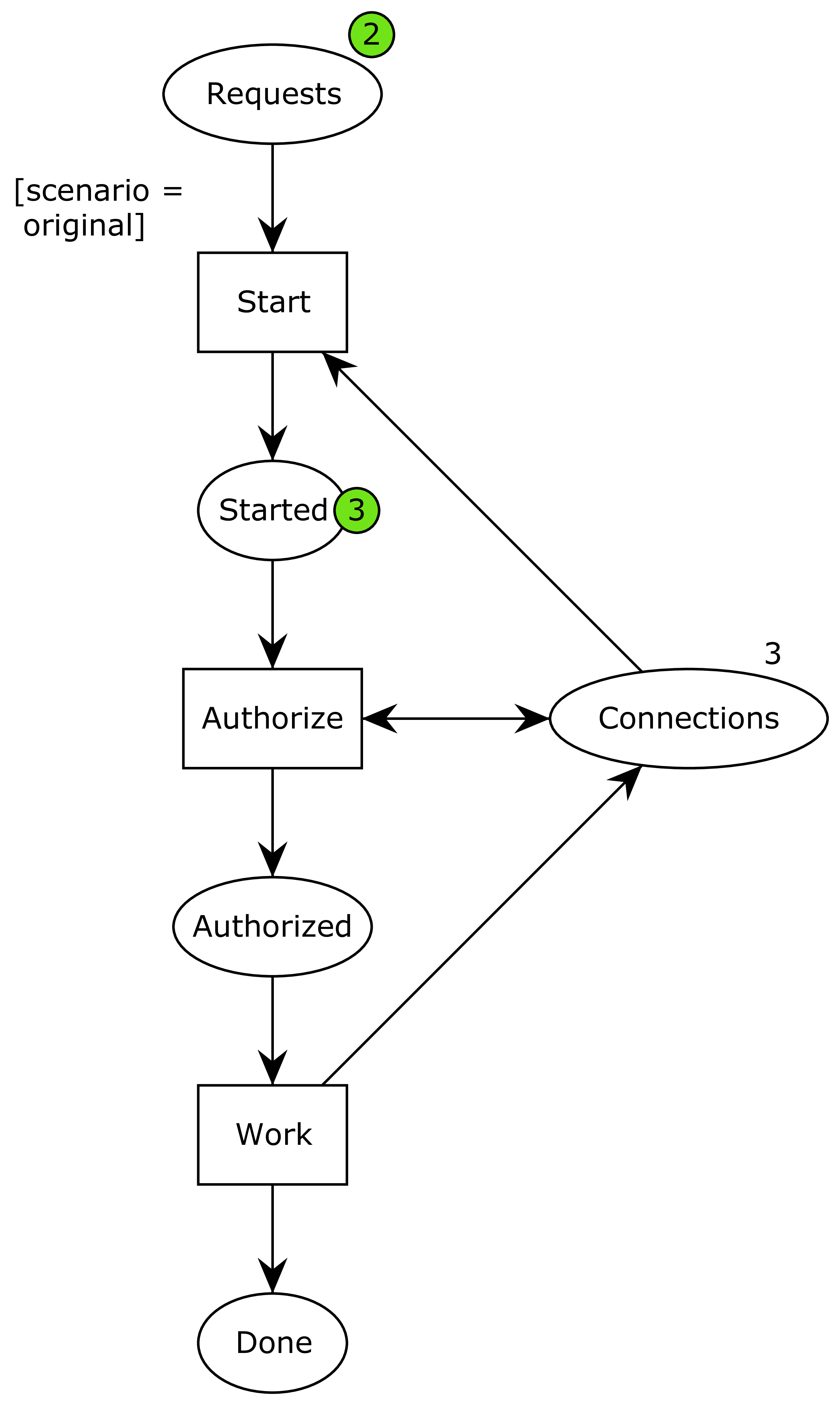
Now, we’re out of connections (the 3 on connections just indicates how many connections are initially present; there’s no current connections available as indicated by the absence of a green circle). This is what caused an issue in our application.
To fix this, various solutions were devised. The simplest one was simply to increase the number of available connections. Basically, we increase the pile of chopsticks from 3 to 10:
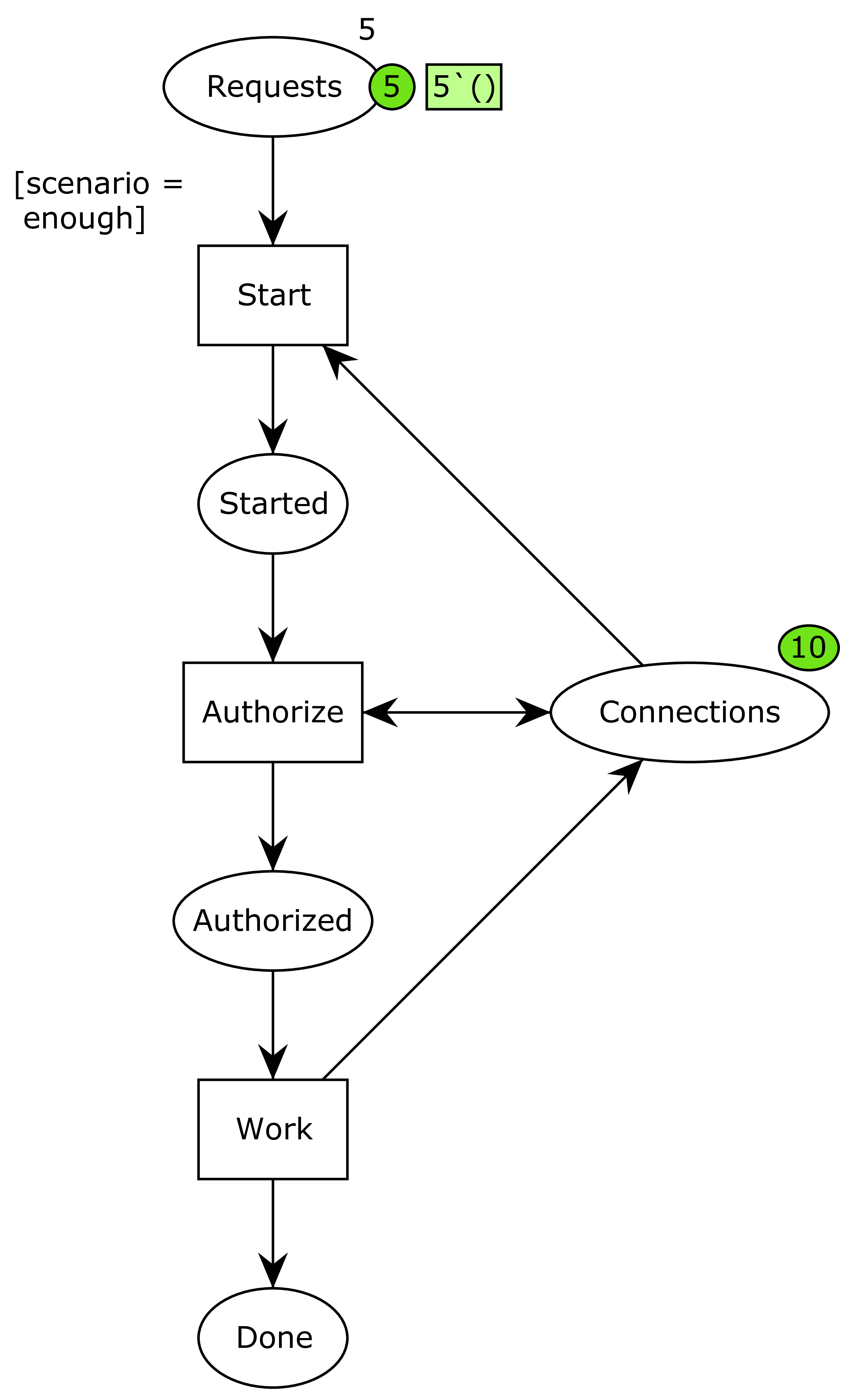
Now, we have 10 connections, and playing around with the system indicates it is now ok. to demonstrate this resolves the issue, we turn to state space analysis. We just use the standard report of CPN Tools, which can list dead and home markings. That is states where the system can perform no further actions and states the system can always reach. For the original system, that part of the report looks as follows:
[raw] Home Properties————————————————————————
Home Markings
None
Liveness Properties
————————————————————————
Dead Markings
[5,14,23,37]
[/raw]
We see that the system has 4 dead states. One is the deadlock above, and two others are with either one or two of the remaining processes in the done state, but otherwise with the same deadlock. The final state is the desired state: all processes are in the done state.
For our new system with 10 database connections, we instead get:
[raw] Home Properties————————————————————————
Home Markings
[56]
Liveness Properties
————————————————————————
Dead Markings
[56]
[/raw]
One one state (number 56) is dead and this state is a home marking, i.e., it is reachable from any other state. That means that from any state of the system, it is possible to get to the dead state. What does that state look like, you ask? Well, like this:
We see that all 5 processes have finished processing and all 10 database connections have been returned. This state is dead in the sense that the system doesn’t progress, but it doesn’t do that because there is no more work to be done. CPN Tools cannot tell the difference between “the system is done” and “the system is locked up.” Furthermore, as this state is a home marking, it is possible to reach it from every other state. It is in other words not possible to drive the system to a state where it is impossible to get to the end state where all work has been performed. Bill Gates was right but off by a factor of just over 3.
Of course, this solution has the big issue that if we increase the number of requests to 10, we run into the same issue as with the original solution. This might be acceptable for a quick work-around, but introduces a relatively simple DoS attack: just send in a million requests and you are highly likely to lock up the application so it won’t be able to recover. Back to the drawing board.
What if each philosopher was able to eat using just one chopstick? Maybe they are having steak or soup where the number of chopsticks makes no difference. In our application, this would mean changing the transaction from REQUIRES_NEW to REQUIRED. Model-wise, it would look like this:

The only change is that now authorize no longer requires a connection. In terms of the application, this means we write to the audit log in the same transaction context as performing the actual request.
The same analysis as before shows that this also solves the issue; we have just one dead home marking, and it is the one where all work has been performed and all database connections returned. This solution does change external behavior of the system, however, so we attempt to alleviate this.
The @Transactional annotation also has a mode NOT_SUPPORTED, which pauses the current transaction and continues in another undefined context. On paper this sounds ok: we pause the transaction with the actual work and write to the log independently of this.
The devil is in the details. And the detail are in the ninth circle of hell. Ergo the devil is in the ninth circle of hell. The details are: what exactly does “pause the current transaction” mean? And what is the explicitly undefined context? One way to interpret it is “put the current context in a separate paused state” and “use a reserved special context,” as illustrated in the below model:
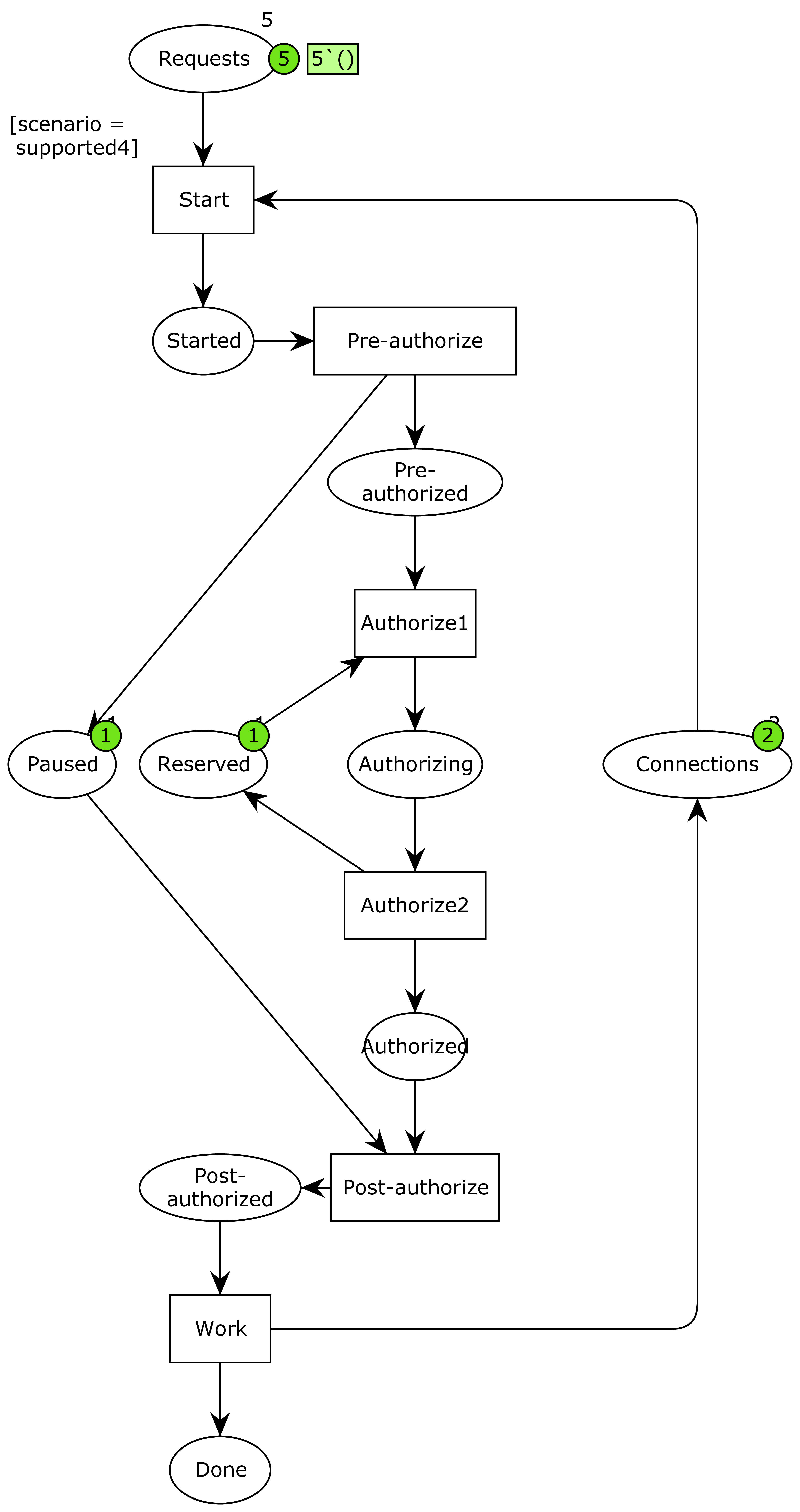
Now, we have introduced pre- and post-authorization steps where we pause the current connection, and the actual authorization is split into two: one where the reserved connection is acquired and one where it is put back. Otherwise, it’s the same model.
While we could probably argue that the previous models were simple enough that their correctness was obvious, this one is quite a bit more involved. The mighty computing machine is not in doubt, though: this model is every bit as correct as the others (except the original).
The issue now is the two points of ambiguity about what it means to pause a connection and what the undefined context is. It is possible that pausing a context just means putting it back in the connection pool. It is also possible that the undefined context is just another connection pulled form the standard pool. Finally, it is possible that both of these are true. This leads to the three models:
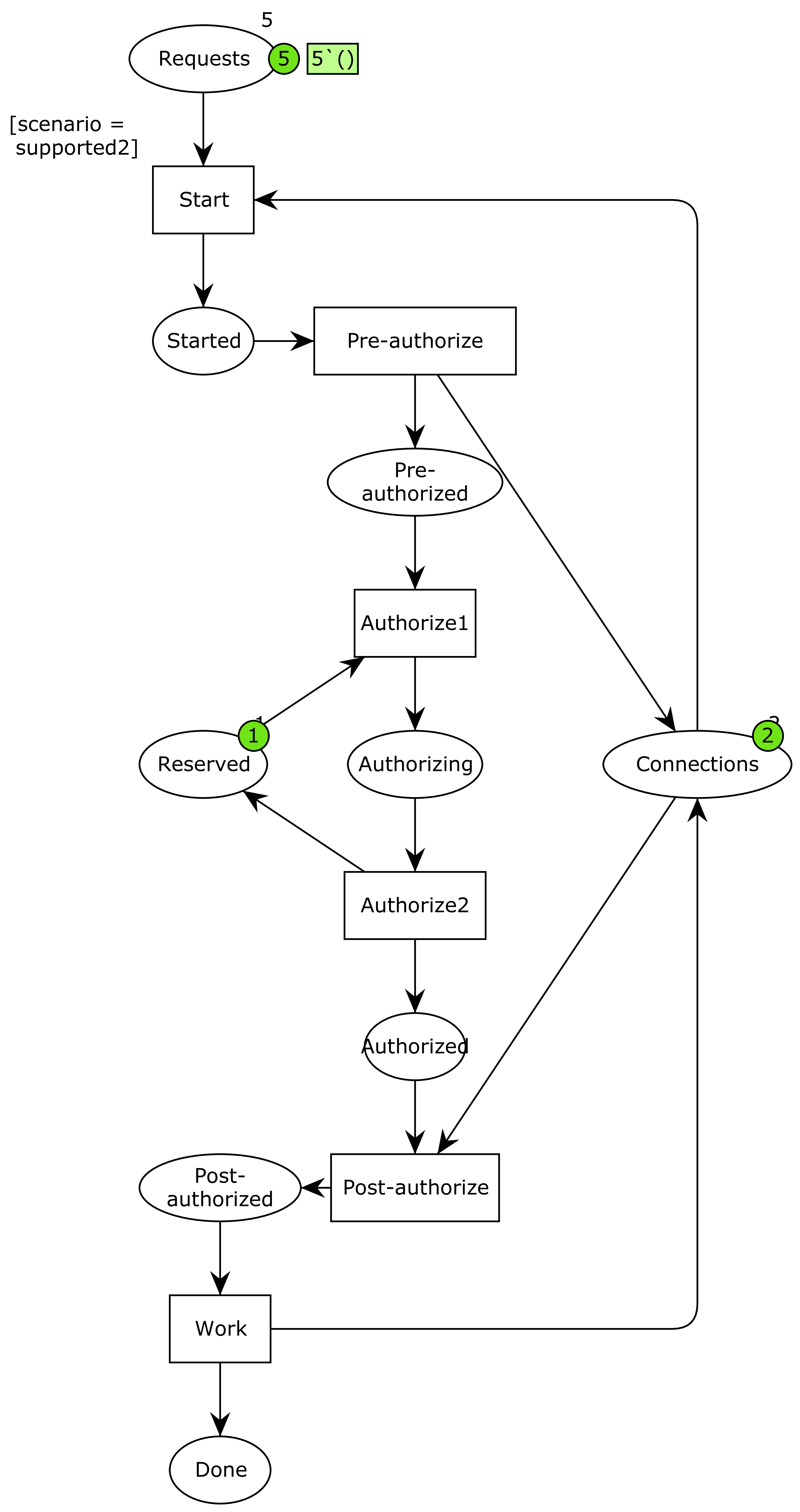
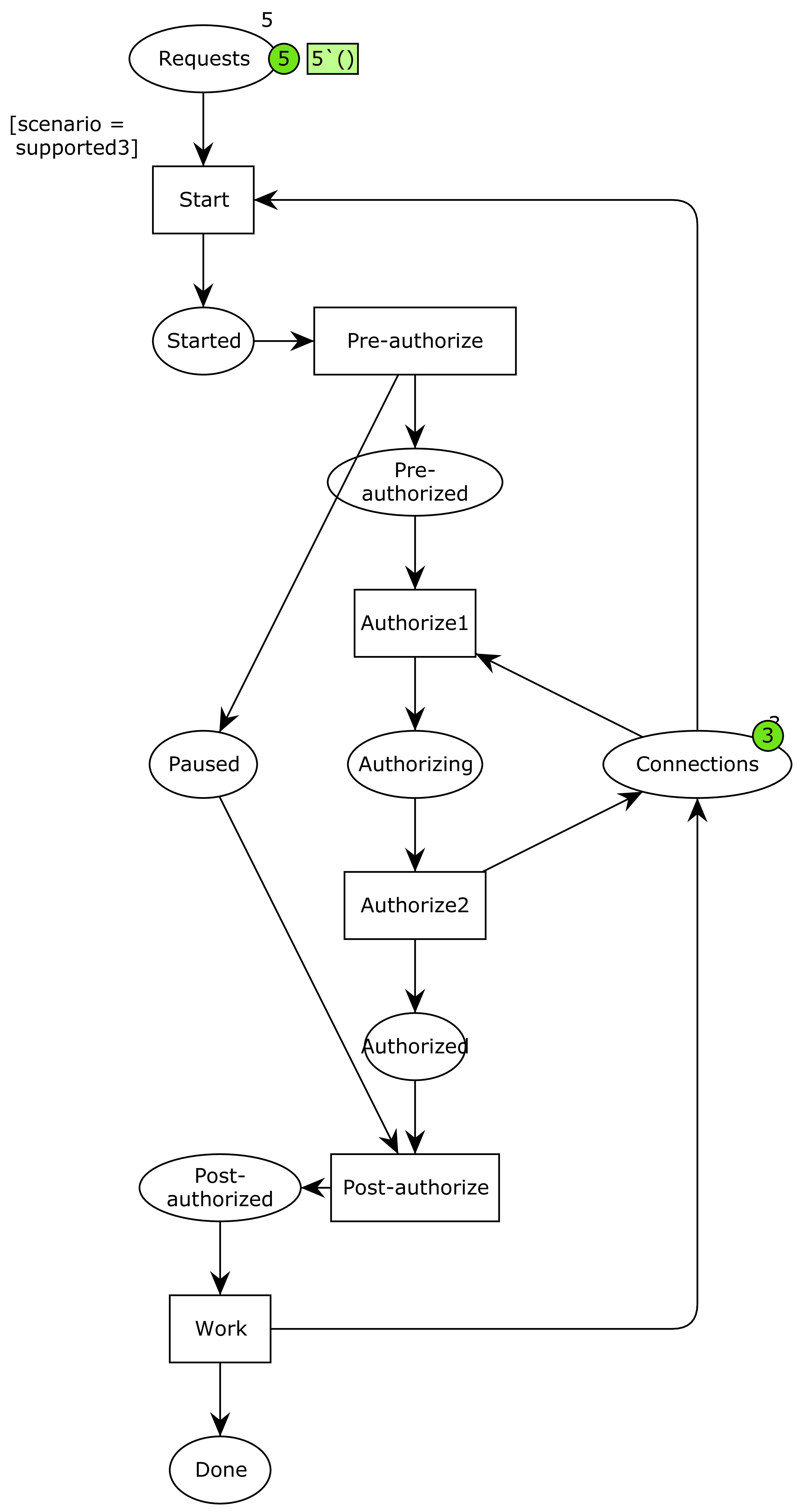

No problem – we just model each of the cases, analyze them and prove them correct? Right, except one of them doesn’t pass validation. This is where the tool support comes in handy. Which of the three above models will exhibit a deadlock?
Well, it’s this one:
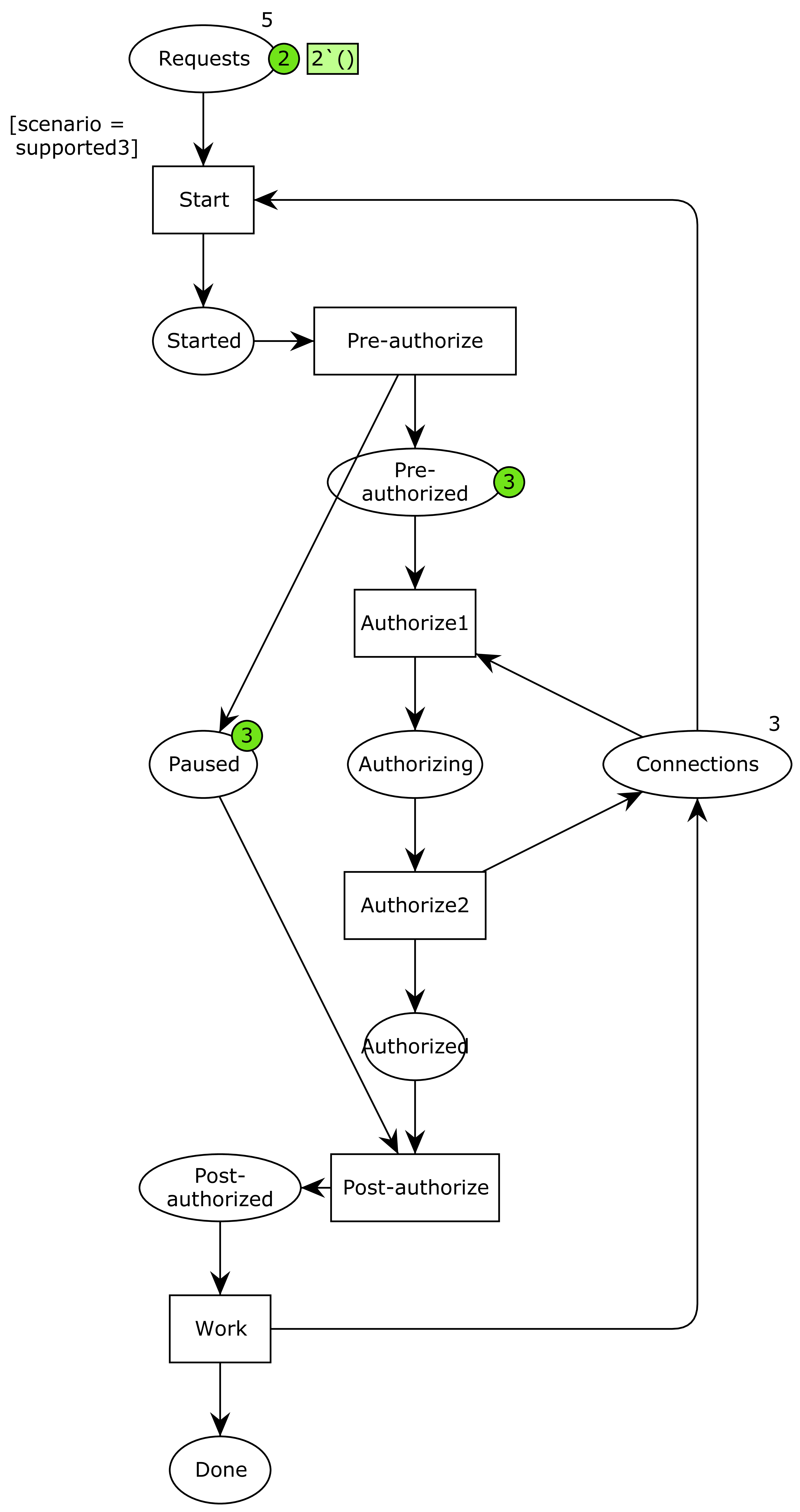
Basically, we now have the same issue at the authorization as before, and pausing the connection does nothing to solve it. I had not thought this configuration would cause issues. Well, I mostly didn’t bother thinking much about it because I was thinking about the configuration where connections were put back in the pool and the undefined context pulled form the pool as well. I could see it was much more complicated, but might allow a notion of progress because more connections were made available when needed, but has a bit of a hard time seeing if the processed could get stuck in the pre-authorized state here. It turns out they couldn’t.
As we don’t want to make the implementation dependent on implementation details like this, this approach was rejected.
This is the solution we ended up going with. Instead of having a fixed connection pool, we allow the pool to increase and decrease in size (the extension in red). This corresponds to the waiter bringing the philosophers more chopsticks as needed and taking them away again when they are not.
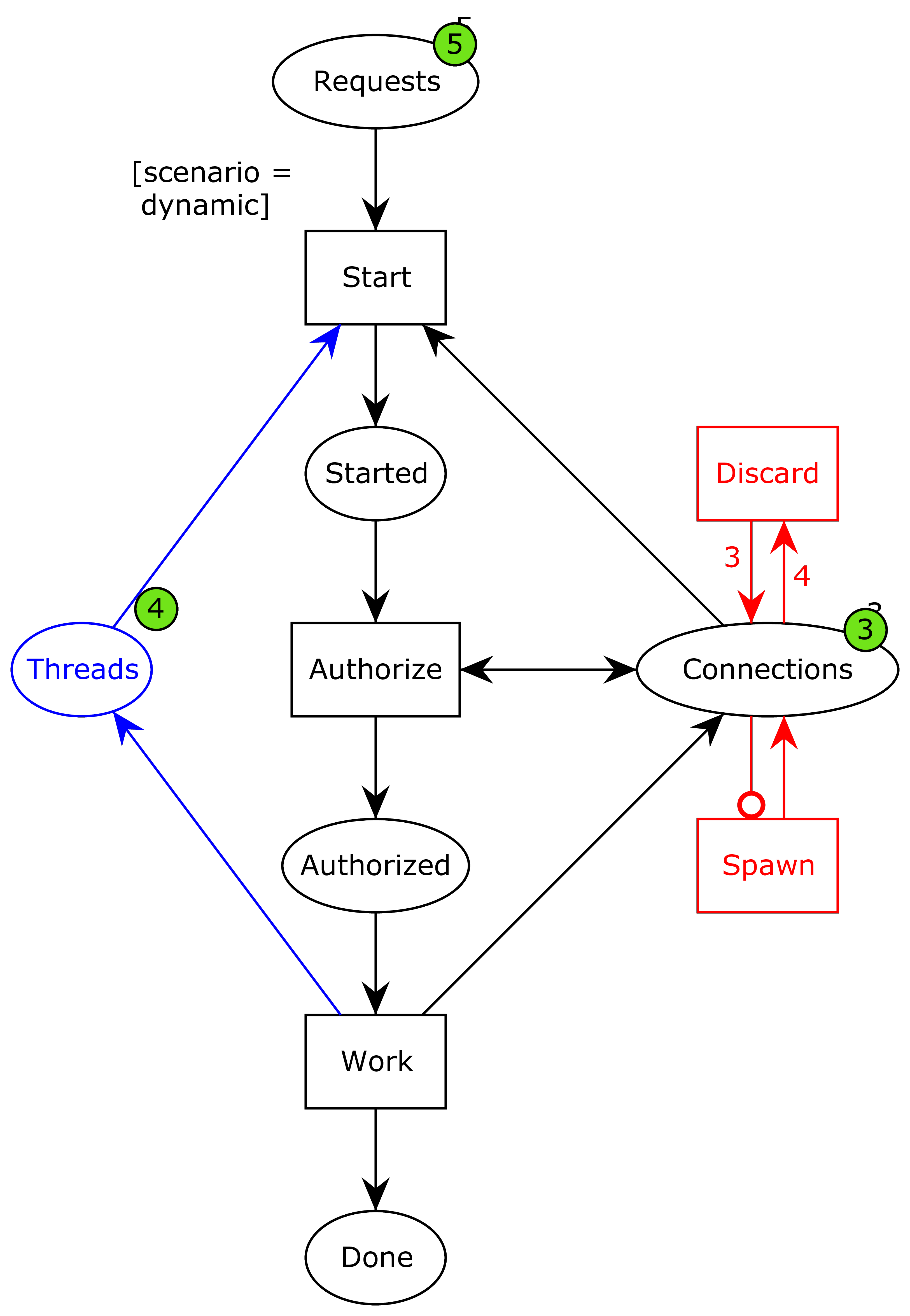
Now, when we have consumed all available connections in the pool…
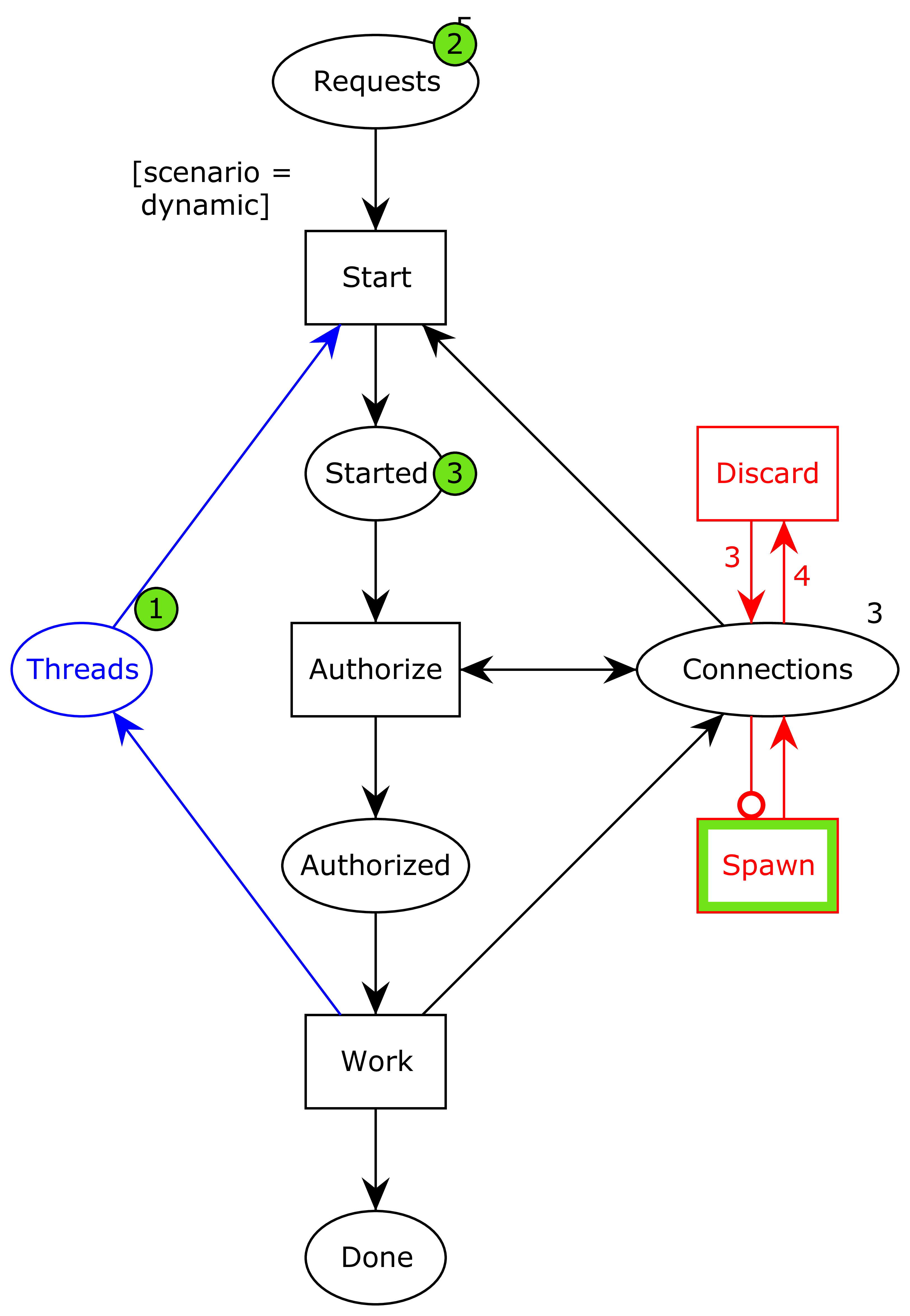
…the system can spawn a new connection into the pool, and the system can continue…

…albeit not infinitely. We have also added the blue part, which models a thread pool. In order to remove a resource exhaustion DoS attack allowing attackers to spawn unbounded threads by sending many requests, we have introduced a thread pool. That means that even though a connection is available and a request is ready to be processed, the system does not start the final process, but instead waits until some of the already started processes are finished.
This final recommended solution is a bit more complex due to the introduction of the thread pool, but can just like most of the other dining philosophers variants be proven to have exactly one dead home state, and that this state is the desired one where all work has been performed.
By the way, the discard action which is responsible for removing database connections when the pool gets too large has no impact on the correctness of the system. It is there purely to ensure we have exactly one end state; otherwise, we would have a couple with different number of connections in the connection pool at the end depending on how many times we ran out of connections during the execution. Also, it makes the model more accurate to reality. That’s totally the reason, not that I wanted a simpler narrative for the model. Nope. The reality thing.
This shows a nice example of how colored Petri nets were used in a real-life setting. First to illustrate an issue and then to illustrate a handful of solution proposals and their up- and down-sides. Finally, we also used formal analysis to prove that the proposed solution despite the introduced complexity does not have the issues we originally set out to fix.

Hi Michael,
Great explanation of how you solved the problem!
I wonder if you can share the cpn file and java files?
Is the implementation from the cpn diagram very difficult to implement in Java?
Thank you,
Duncan
Hi Duncan,
Thanks for the kind words.
I am afraid the model has been lost to time, but it contains nothing more than what is shown in the images. The Java code belongs to a customer, so I cannot share that either.
The implementation is very simple, though. We use any JavaEE container (we used Tomcat, but any will do, as will a more modern micro service container like Spring Boot) for managing the connection pool; it can be configured to extend dynamically or with a maximum size. The model allows extension without border, but you can convince yourself (or inspecting the bound of Connections) to see you actually can set a global max.
Instead of using nested transactions, we just removed the inner transaction which is the root cause of the issue (so don’t use REQUIRES_NEW, any of REQUIRED and MANDATORY are fine but have slightly difference semantics). That is how they are used normally anyway; the use of REQUIRES_NEW was an attempt at slightly finer grained transaction control that turned out to not be worth the problems after all.
Regards,
Michael