I have written a bit about how I wanted to do reporting in the MBT Workbench. The idea was simple: just extract all the results, dump them into a database, and use an approach similar to what we did back in the days using ASAP: generate a report using an off-the-shelf business-intelligence suite, here JasperReports. I even got as far as setting up a simple report in the MBT Workbench, but then I got a better idea…
The MBT Workbench simplifies the model-based testing paradigm and allows users to easily set up tests. It can translate comprehensive 100% coverage tests to logical test cases easily understandable by test engineers. Originally, my plan was to also generate colorful test reports, as I saw them from other tools (for example JUnit, Serenity, or ReadyAPI/SoapUI).
The real question is not whether I could generate such reports, but rather whether I should. I could spend time creating prettier,
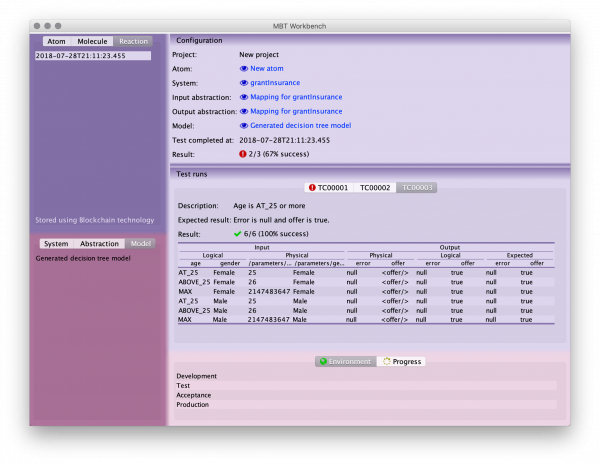
I went and removed JasperReports from the MBT Workbench, and replaced it by a relatively simple native component that displayed the same information:

At the top, we see the test configuration where all artifacts are linked directly. We also get a summary of the results. At the bottom, we see results for each test case and individual runs; failed cases and runs are highlighted.
I probably spent way too much time customizing my table, but I really like the end result. It is a standard JTable (really JXTable or JXTreeTable) meets LaTeX’
As handy (and pretty) the view is for displaying results, it is not very handy for convincing somebody else you have tested everything necessary. To do that, the new strategy is to just use one of the established tools, and focus MBT Workbench on what distinguishing it: making it easy to write good tests, instead of running said tests.
I am therefore implementing a code generator, which can generate test classes, that can be run using any standard tooling, either manually or as part of a CI/CD pipeline to generate whatever type of report, integrating with
The biggest obstacle to code generation I have currently is that at some point, I will want to map the values using the configured abstractions. For the input abstractions, I can (in this simple case) precompute the mappings, but for the output mappings, I would prefer to make assertions based on abstracted values rather than exact observed values (in addition to making it possible to ignore parts of the responses that may vary between executions, that also means I can generate the test source without actually invoking the service).
I am thinking that either I will have to add a dependency on Groovy and include the mappings as inline scripts (which does not appeal to me one bit), generate the tests entirely in Groovy (which is less ugly but somehow less appealing as well; why would anybody write something of consequence in Groovy?), or switch to another language which is more native for both scripting and writing tests (I’m here thinking of Kotlin, which is the hot new and therefore appealing but also sounds like cutlet which, being a vegetarian, repels me ((Kidding, I don’t care about that one bit but it does remind me of that.)) ).
Generating JUnit tests (complete with Maven projects to pull in all dependencies and run them will be useful but not revolutionary in any way. I think that where this approach really shines is in generating Serenity tests for testing graphical applications. Serenity generates very pretty reports, but I disagree with a couple of its decisions. In particular, the mapping between its obscure “natural language like” DSL and the web-page is a messy piece of junk that should be generated by a computer, and I believe the MBT Workbench will be just the tool for that.
I am currently torn between dropping database backing of test results entirely, or doubling down and making it possible to make simple visualizations of trends (including viewing previous results). In favor of getting rid of it is
But more importantly, take another look at that pretty table I made. It just looks so pleasing.
