About a week ago, I started writing about model-based testing. It’s a testing methodology where the focus isn’t on making klogical test cases, but rather on making an abstract description of the system under test and letting a computer perform an exhaustive test. I introduced some of the issues with the method when faced with reality as I see it, and proposed a tool that would make the method available without most of the issues. Now, a week and 4561 lines of Java code later, I’m well underway implementing the tool. It is still in the early phases, but I wanted to give a sneak peek of what it can do so far.
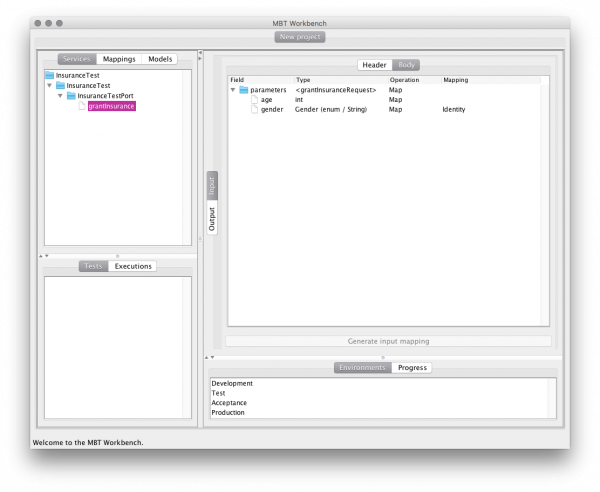
Let us first summarize the conceptual meta-model for the operation of the tool. That’s of course the first thing you do. It was of course not the first thing I did, but a thing I did for this post.
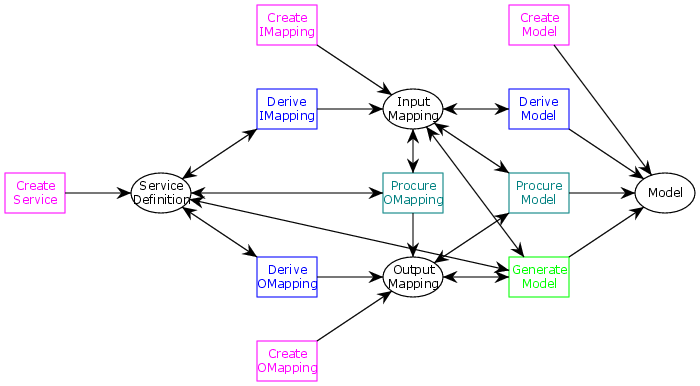
In the figure, artifacts are ellipses and generations are rectangles (it’s really a Petri net but who cares). Magenta steps are manual, blue steps are tool-assisted, teal steps are semi-automatic, and green steps (step) are automatic. For readability, I have only included the interactions that generate artifacts; we should also have a a big ol’ green step that uses all artifacts and does model-based testing.
If you recall, we have 4 types of artifacts: service descriptions describing the system under tests, models providing an abstract executable description og the system under test (the specification), input mapping transforming input variables of the model into inputs for the service, and output mappings transforming outputs from the service into output variables of the model. Each of the 4 artifact types can be created manually; in fact creating the service description is out of scope of the MBT Workbench, so that is the only way to create this.
We can derive input and output mappings from service description. We inspect the definition and allow the user to describe how service requests relate to model variables. We’ll get into more detail about this later so hopefully that will become clearer.
While we can derive an output mapping from the service-description alone, we can also additionally use an input mapping. When we have a service description and an input mapping, we can just blindly execute the service and let the user procure an output mapping based on actual service results.
A model can be generated more or less automatically depending on how many artifacts are available. If we have an input mapping, we can derive model input variables and let the user specify output variables and the relationships between them. If we additionally have an output mapping, the user only needs to specify the relationships between variables, as output variables can also be derived. Adding a service description to the mix allows us to call the service and automatically derive a relationship between input and output.
As running example, we’ll use the insurance example from the first post: an insurance company grants car insurances based on age an gender, but does not grant them to men under 25 because they are a greater risk to the holy profitability. This web-service is described using a simple WSDL:
[xml] <wsdl:definitions xmlns=”eu.brinformatics.mbt.example.insurance.wsdl”xmlns:tns=”eu.brinformatics.mbt.example.insurance.wsdl” xmlns:wsdl=”http://schemas.xmlsoap.org/wsdl/”
xmlns:soap=”http://schemas.xmlsoap.org/wsdl/soap/” xmlns:xsd=”http://www.w3.org/2001/XMLSchema”
xmlns:data=”eu.brinformatics.mbt.example.insurance.xsd” name=”InsuranceTest”
targetNamespace=”eu.brinformatics.mbt.example.insurance.wsdl”>
<wsdl:types>
<xsd:schema xmlns:xsd=”http://www.w3.org/2001/XMLSchema”
xmlns=”eu.brinformatics.mbt.example.insurance.xsd” xmlns:tns=”eu.brinformatics.mbt.example.insurance.xsd”
targetNamespace=”eu.brinformatics.mbt.example.insurance.xsd”
elementFormDefault=”qualified” attributeFormDefault=”qualified”>
<xsd:simpleType name=”Gender”>
<xsd:restriction base=”xsd:string”>
<xsd:enumeration value=”Female” />
<xsd:enumeration value=”Male” />
</xsd:restriction>
</xsd:simpleType>
<xsd:element name=”grantInsuranceRequest” type=”tns:grantInsuranceRequest” />
<xsd:complexType name=”grantInsuranceRequest”>
<xsd:sequence>
<xsd:element name=”age” type=”xsd:int” />
<xsd:element name=”gender” type=”tns:Gender” />
</xsd:sequence>
</xsd:complexType>
<xsd:element name=”grantInsuranceResponse” type=”tns:grantInsuranceResponse” />
<xsd:complexType name=”grantInsuranceResponse”>
<xsd:choice>
<xsd:element name=”error” />
<xsd:element name=”offer” />
</xsd:choice>
</xsd:complexType>
</xsd:schema>
</wsdl:types>
<wsdl:message name=”grantInsuranceRequest”>
<wsdl:part name=”parameters” element=”data:grantInsuranceRequest” />
</wsdl:message>
<wsdl:message name=”grantInsuranceResponse”>
<wsdl:part name=”parameters” element=”data:grantInsuranceResponse” />
</wsdl:message>
<wsdl:portType name=”InsuranceTestPortType”>
<wsdl:operation name=”grantInsurance”>
<wsdl:input message=”tns:grantInsuranceRequest” />
<wsdl:output message=”tns:grantInsuranceResponse” />
</wsdl:operation>
</wsdl:portType>
<wsdl:binding name=”InsuranceTestBinding” type=”tns:InsuranceTestPortType”>
<soap:binding style=”document”
transport=”http://schemas.xmlsoap.org/soap/http” />
<wsdl:operation name=”grantInsurance”>
<soap:operation soapAction=”grantInsurance” style=”document” />
<wsdl:input name=”grantInsuranceRequest”>
<soap:body use=”literal” />
</wsdl:input>
<wsdl:output name=”grantInsuranceResponse”>
<soap:body use=”literal” />
</wsdl:output>
</wsdl:operation>
</wsdl:binding>
<wsdl:service name=”InsuranceTest”>
<wsdl:port name=”InsuranceTestPort” binding=”InsuranceTestBinding”>
<soap:address location=”http://virtualize.westergaard.eu/ws/insurance” />
</wsdl:port>
</wsdl:service>
</wsdl:definitions>
[/xml]
The details are not essential, but this is a fairly standard WSDL where we define a schema for request (ll. 18-24) and response (ll. 26-32). The request uses an integer input (age) and a custom type for the gender. The custom gender type is a simple enumeration (ll. 11-16). The remainder is a bunch of boiler-plate to tie these types into a SOAP web-service ultimately defined in ll. 60-64.
Enough about that. Let’s load this into the MBT Workbench. When we first start the MBT Workbench and create a new project, this is what greets us:
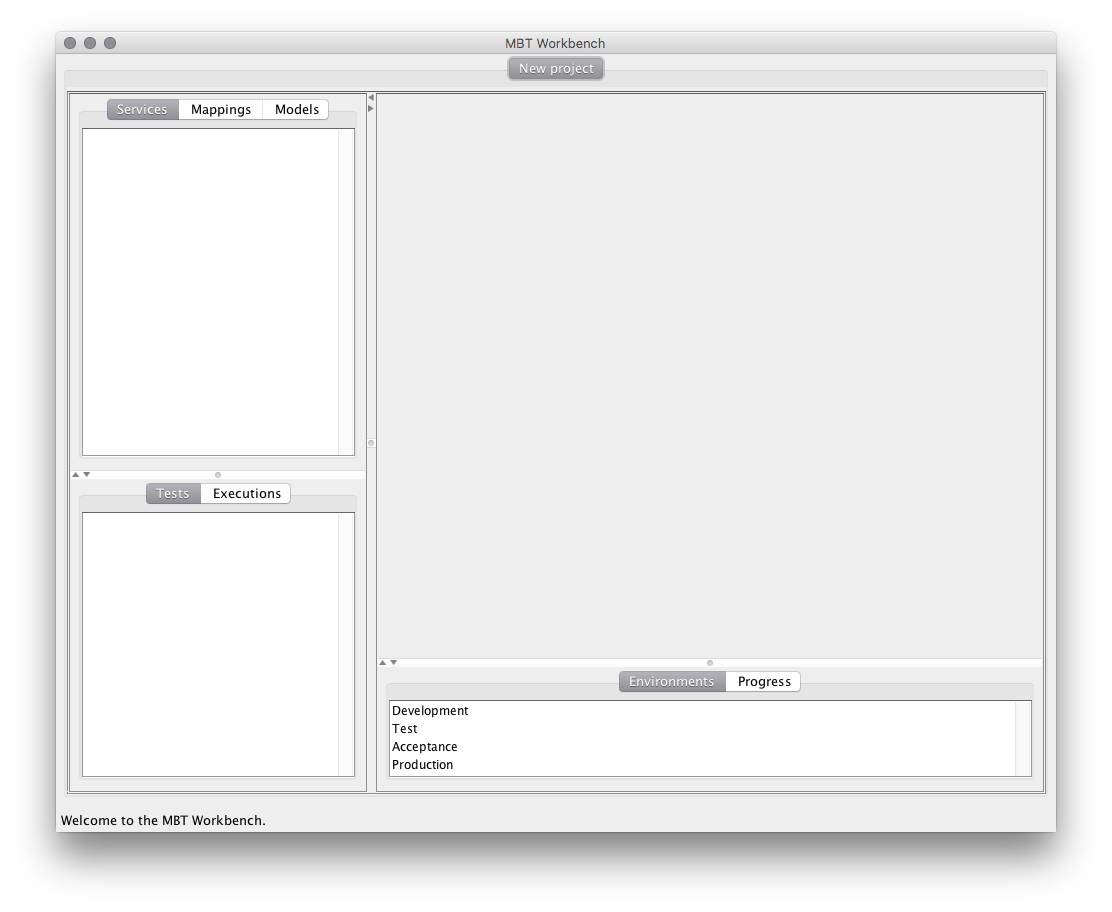
We see there’s a good correspondence with the meta-model. At the top-left we see our various artifacts: services, mappings (input and output mapping are under a single tab), and models. At the bottom left, we have our tests, but we won’t be getting there today. The right-hand part of the application is where most of our work will be done. At the bottom we have a few informational panels which won’t be relevant for a long time.
Loading our definition, the view changes to this:
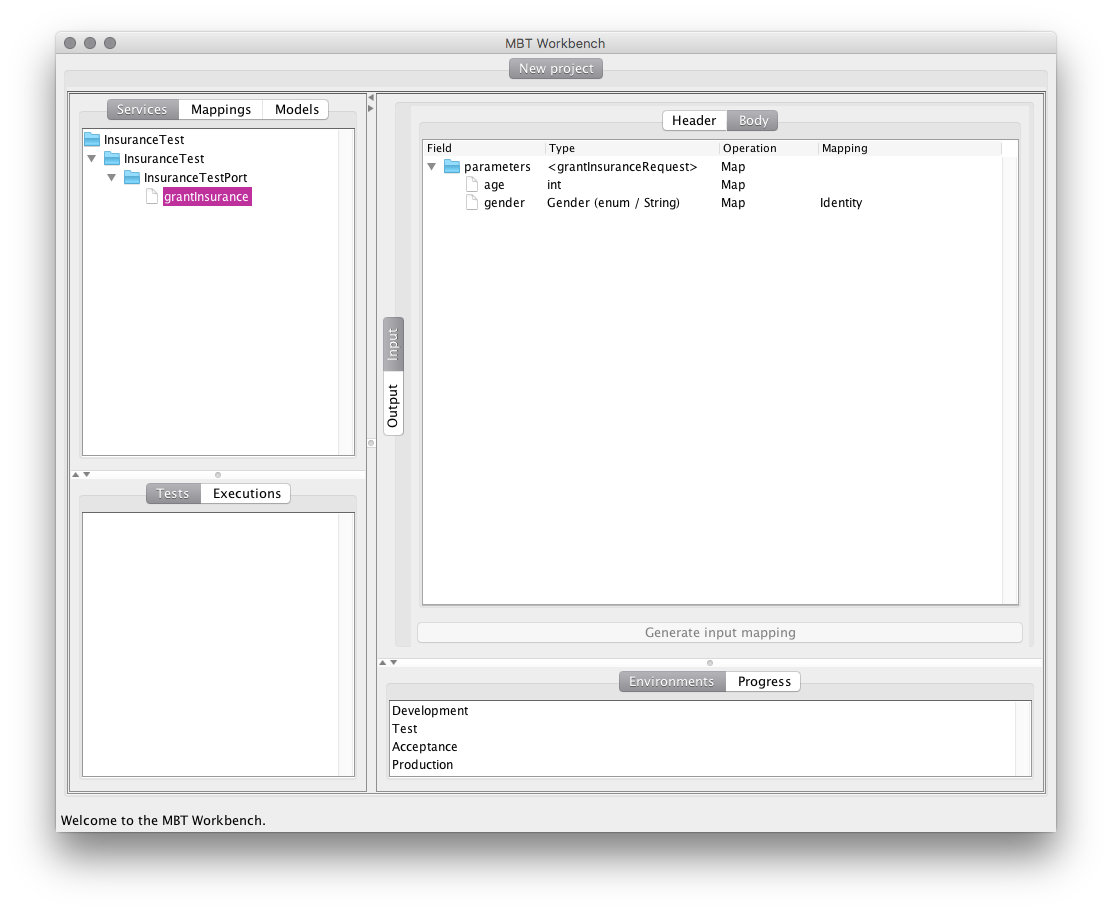
The services view now reflects the service (including a bunch of the boiler-plate which is necessary for general services). The main area shows us a view of the service, which is greatly simplified from the original WSDL. We see the two parameters and their types.
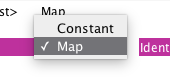 We can decide what to do with the individual parameters, either Map them from model variables, bind them to a Constant value or just Ignore them. The tool automatically filters possible operations and picks reasonable defaults. For example, none of the values in this WSDL are optional, so the tool will not offer to ignore any of them. If the WSDL specifies a default value for any parameter, the tool suggests using the default as a constant binding.
We can decide what to do with the individual parameters, either Map them from model variables, bind them to a Constant value or just Ignore them. The tool automatically filters possible operations and picks reasonable defaults. For example, none of the values in this WSDL are optional, so the tool will not offer to ignore any of them. If the WSDL specifies a default value for any parameter, the tool suggests using the default as a constant binding.
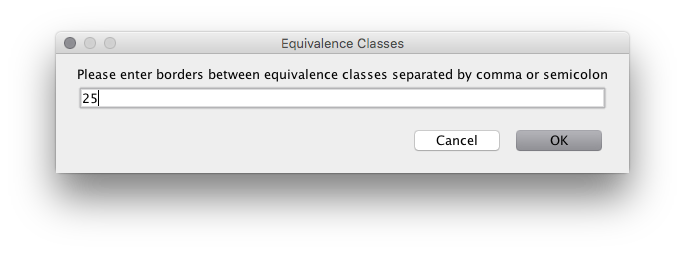
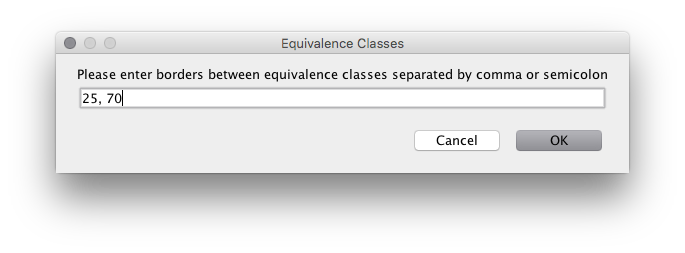
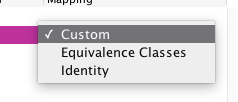 The most interesting variables are ones we bind using a mapping. The tool comes with various mappings that are relevant for different types. Again, the tool only offers relevant values. For the age, we currently get 3 options: a custom mapping, using value-based equivalence classes, or using an identity mapping. The identity mapping just tries using all possible values for the type. This is the default for enumerations and boolean values as they already only have a finite number of options. For the age, the most reasonable choice is the value-based equivalence classes. Selecting this, we are prompted for the relevant values. Remembering the functional specification, we know that the relevant value here is 25:
The most interesting variables are ones we bind using a mapping. The tool comes with various mappings that are relevant for different types. Again, the tool only offers relevant values. For the age, we currently get 3 options: a custom mapping, using value-based equivalence classes, or using an identity mapping. The identity mapping just tries using all possible values for the type. This is the default for enumerations and boolean values as they already only have a finite number of options. For the age, the most reasonable choice is the value-based equivalence classes. Selecting this, we are prompted for the relevant values. Remembering the functional specification, we know that the relevant value here is 25:
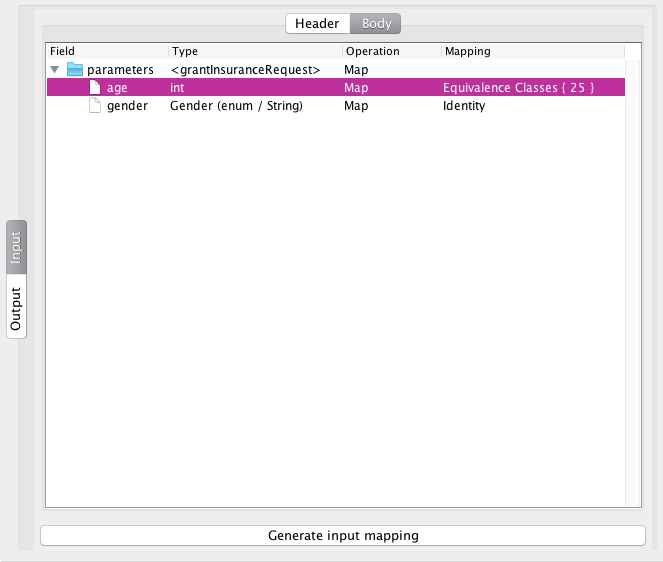
After inputting this, the screen updates, and the button on the bottom becomes enabled, indicating that we have now specified enough information for the tool to automatically derive an input mapping:
 Selecting the identity mapping for integers is allowed, but the button at the bottom will change to “Generate partial input mapping” indicating that the mapping cannot be used as is (this is intended for future functionality where multiple services are composed into a single test).
Selecting the identity mapping for integers is allowed, but the button at the bottom will change to “Generate partial input mapping” indicating that the mapping cannot be used as is (this is intended for future functionality where multiple services are composed into a single test).
Going instead with the more reasonable choice of the equivalence mapping, we can generate an input mapping, and we are nearing the end of what I have implemented so far. As a teaser, here’s what the mapping looks like right now:
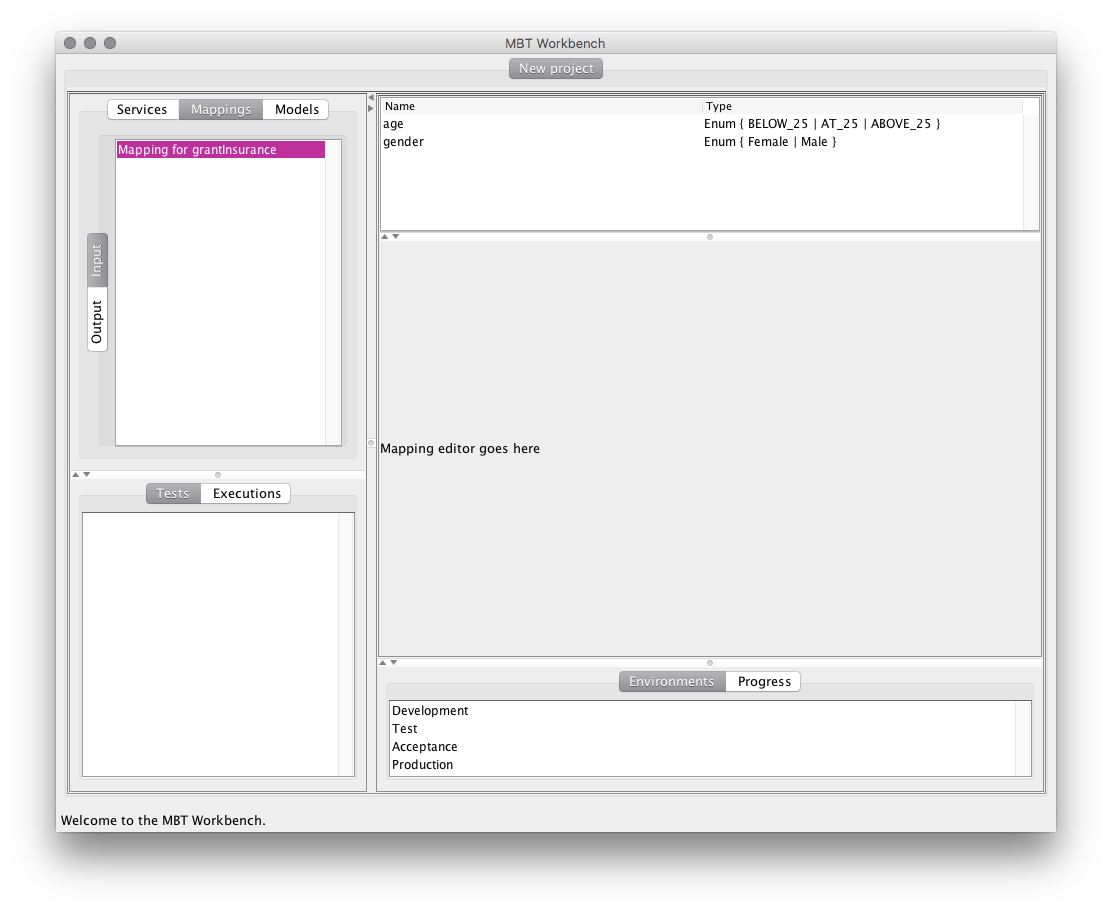
We see we have switched to the Mappings tab and selected the new input mapping. On the right side, the view has changed and now shows us a list of mapping variables at the top and a placeholder for the actual mapping editor. We see the model has derived two variables of type enumeration. The gender variable corresponds one-to-one with the value from the specification and has been automatically populated. The age variable has also been translated into an enumeration with three values, BELOW_25, AT_25, and ABOVE_25, indicating the 3 cases possible when the interesting value is 25.
In an alternative universe, where the age 70 also matters – perhaps because nobody above the age of 70 should be allowed in traffic:
Here, the tool would generate an enumeration with 5 possible values:

The tool is built on Java 8 using Swing as UI toolkit and Spring for application integration.
I seriously considered using JavaFX but I have less experience (consultant-speak for none whatsover) with that than Swing, and a couple quick searches indicate it might not be completely ready for prime time (for example, something like the tree table I used for displaying the web-service should not be available). Most importantly, I wanted something simple enough that I could focus on the actual functionality, so I went with what I knew.
The application is based on the model-view-controller design pattern, and makes heavy use of the Java Observable/Observer class/interface couple.
Spring allows simple integration of the application, especially using autowiring of objects. This allows me to construct the user-interface without having to pass around references, but can just autowire the appropriate components into place.
Autowiring also allows me to add new mappings of variables easily. The editor simply autowires all possible mappings and just filters them for appropriateness. The same trick is used for variable type editing (which I am working on right now).
I can also take advantage of Spring type conversion for managing the user interface. I have several different types of objects viewable in the left-hand index (right now one kind of web-services and input mappings, but fully expect to add many more types), and instead of having to implement detailed display logic, I simple implement a converter from the model object to the view object and have simple generic action code which attempts to convert a model object to a corresponding view object and shows it.
For web-services, I rely on Apache CXF, which can parse the web-service description for me, allow me to inspect it, and finally execute it, all without me having to see too much XML. CXF also supports JAX-RS, so with a bit of luck I can also implement REST web-services without too much hassle. For inspection, I don’t use the “standard” XJC compilation, but instead use CXF’s dynamic client, which can do this and generate JAXB classes on runtime.
One problem I am facing is that I need a combination of Java’s collections framework and the Observable/Observer class/interface. I am currently using the JavaFX ObservableList (and ObservableSet and FXCollections), which serves my needs, but adds a dependency on JavaFX, which, it turns out, is a problem on Linux (JavaFX is not distributed as part of OpenSDK as used in CentOS, which I am using on my CI server). The top results on Google for alternatives don’t really seem viable right now (the Groovy one is weird and not generics-aware, the Eclipse one trades JavaFX for some subset of Eclipse which is no better, and the Apache Commons Events one seems abandoned). If anybody knows of good alternatives, please let me know! I am certain I once implemented something like this, but that was 10-15 years ago and I would rather have a 3rd party maintained one rather than having to roll my own (also I think it was a part of the BRITNeY Suite, which I cannot find the source for right now).
I also need a bridge between Sets and Lists. It needs to be backed by the same data (or synchronized between the two). This is needed for displaying variables (the List aspect) as they are backed by Sets. The major issue is that I would need notifications to be sent for both aspects of the data structure regardless of which one was added, and this is not immediately possible using the FXCollections wrapper (notifications are not sent when changing the underlying collection), so I would either set up a bridge synchronizing values between the two structures (quite doable) or implement an observable interface on my own. As I’m considering replacing JavaFX with “something else” I am not keen on implementing the bridge until I have a resolution to that issue.
For the next steps, I’m working on implementing the mappings. My plan is to use Apache Commons JXPath and either Groovy or Beanshell for the specification.
JXPath is an XPath implementation for Java objects. It would pick out the components of the request to (and later response from) the web-service, and I would then specify the mapping using a simple script language. JXPath allows me to use a technology that is very similar to the web-service technologies already used while remaining largely agnostic of the concrete web-service technology (i.e., it should also work for REST/JSON services if I specify the JSON using, e.g., Jackson).
For scripting language, I really like Beanshell (which I also used in the BRITNeY Suite back in the days), but unfortunately this seems super-abandoned. Groovy seems like what the young people are using today, and for specifying simple mappings it’s probably ok.
In conclusion, the MBT Workbench is coming along nicely. If you have any concrete web-services, please send them to me so I can test them. For some types, I need to inspect the schema as well (for example to extract values allowed for enumerations and length/value/pattern restrictions for simple types), and SOAP web-services can be specified in many ways, so I would like to test my inspection using as many services written in as many different styles as possible to make sure the tool is as widely applicable as possible also for services it was not directly written for.
I am also open for ideas. I already have a couple more ideas not reflected in the original meta-model (logical test-case generation, fuzzing values based on input mappings, specification optimization/validation/improvement, partial and composable/decomposable specifications, etc).
