So, for my GitLab project management tool, I Я Project Manager, I need access to a lot of GitLab artifacts. So many, really, that loading takes a good few seconds, which is maybe acceptable for a first load (I can slap up a progress bar with some “witty” progress messages), but not for intermediate page load. Thus, I want to employ the oldest trick in the book, caching, but due to an atypical usage pattern, I cannot blindly use regular caching, so instead I came up with the CacheRegistry which seems extremely generic, yet I have been unable to find anything like it so I decided to write it up here.
Caching works by moving a copy of data closer to where it is needed. This typically works better if many people need to read the data and comparatively few people need to write it (as a write means the local copy is no longer current and “something” needs to be done about that). Closer to where it is needed can mean many things: moving to CPU cache instead of RAM, moving to RAM instead of disk, moving to disk instead of the network, or moving to a local web proxy cache instead of a remote web-site. The “local” data typically replicates just part of the remote data and trusts that copy to be fresh for a limited time (from seconds to hours or days for certain data). When data is first needed, the cache fails, retrieves the data from the remote copy, and returns the data. On subsequent requests, the data can be served from the local cache instead of the remote copy, yielding a speed improvement. If somebody else updates the remote data, the local copy is no longer fresh. In some cases, this is not a huge problem (getting a web-site from a few minutes ago is probably acceptable) and in some cases it is (if I want to withdraw money from my account, it’s better to be 100% certain the money is there). To handle that, the cache needs to be invalidated at times.
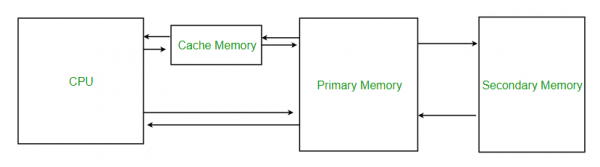
Caches can be invalidated in many ways. The three most obvious ones are 1) that the remote server notifies everybody that their local cache is no longer valid when that is the case, 2) that local clients contact the remote server everytime to check whether their cache is still up-to-date, and 3) that the client assumes the data is valid for a certain amount of time and then checks with the server. The first option requires that the server keeps track of all clients. This is only feasible in cases with a limited number of clients, and requires that we can make the server handle this responsibility. 2 has impact on performance; while checking whether a remote copy has been updated can be faster than fetching the data altogether, it is certainly slower than not doing to. 3 is ok if the data can be assumed to be fresh for long enough.
For my PM tool, none of these compromises are really good. I need to synchronise 1000s of pieces of data (groups containing projects containing milestones containing tickets), and to display a coherent whole, I need to synchronise all of it. Worse yet, I need all of the data to be reasonably fresh; if somebody closes a ticket, it should preferably be visible within seconds or a few minutes at most. I cannot change the server as I fetch all my data using CRUD/BREAD web-service operations from a server I don’t control (I know of GitLab webhooks, which in principle can be used to make this work, but that’s a hassle to get going). Since I have 1000s of objects, I cannot rely on checking the server for updates; just the round trip will kill any performance (the problem is latency, not throughput). Finally, I cannot really rely on a timeout based cache, as I need all the objects simultaneously, so instead of performance being slightly impacted, instead my application would grind to a halt whenever the timeout occurs so a short timeout is out of the question, and a long timeout would mean the data becomes stale.
This situation is closer to that of most ORM tools like Hibernate: they represent relational data from a database as objects in a JVM application. There are a lot of objects and a local cache can speed up performance greatly. Heck, the objects in memory directly serve as a cache. Hibernate forces the developer to manually load and store objects, though, and conflicts are mostly resolved on write. Furthermore, Hibernate assumes exclusive access to the database in the sense that it provides no support for automatically discovering externally made changes. Also, there doesn’t seem to be a generally usable library for Hibernate’s own caching.
So, what I want is near-real-time local caching of 1000s of objects which change often, but only a few actually change. I need access to all/almost all objects each time. Fortunately, my objects are not random: they live in a (fairly) strict hierarchy: a group contains projects, a project contains milestones, and a milestone contains issues. There are couple exceptions to this (projects also contain issues and issues do not need to live in milestones, but let’s ignore that for simplicity). Unfortunately, I cannot just cut off at a certain level like I had hoped. My tool has a view where tasks assigned to each resource are shown. The only way to find that information is to inspect individual issues, as issues can be passed between different users, and my tool aims to expose this history. So, my caching library builds on two kinds of relations: composition and dependencies.
Composition is a parent-child relationship and a dependency just means that one object depends on the data in another. Using these, it is possible to keep data reasonably up-to-date without fetching all data every time. GitLab’s API supports CRUD (create-read-update-delete) operations, though really it is the more common (but less spoken about) BREAD operations (browse, read, edit, add, delete); the last 4 are just renaming of the CRUD operations to provide a better initialism, while “browse” is new: it allows us to get a list of all objects of a given type. In GitLab, I can get a list of all issues in a milestone, but I don’t get all details for all issues. To get the details, I need to explicitly fetch them from the issue. But in the overview, I do get a “last changed” date for tickets. So, if I say that a milestone contains issues, which contain details, I can fetch all issues with just one call, and fetch all details for each issue with one call per issue. But if the issue has not changed (the “last changed” date remains the same), I can also be confident that the details are the same. This is the crux of the composite relationship: if a parent has not changed, none of its children have. This means I can check freshness of my cache by simply checking freshness of the parent. If the parent is unchanged, so are all children. If the parent has changed, I need to fetch it again, and check some or all of the children as well. This allows me to check all tickets of a milestone using a single web-service call per milestone, instead of a call per issue, leading to an immense speed-up (1 web-service call instead of 20-200).
If a parent is unchanged, then so are all children via contraposition leads to the fact that if a child has changed, so has its parent. This allows us to invalidate caches efficiently as well. If a suer drags or otherwise changes a single task in my tool, I need to not only update that taks, but also its (transitive) parent(s); for example, completing a ticket, changes the completion percentage of the enclosing milestone.
In fact, this notion of being dependent on changes to one cached object is taken further in the form of object dependencies, the second type of tracked relation. A dependency simply says that the value of an object depends on the value of another object. If the cache of an issue is invalidated, all tasks that depend on that object also automatically become invalid. Invalidation does not mean that the value needs to be recomputed here and now, but that it needs to be done at some time before the value is needed. By tracking these relationships explicitly, it becomes much easier to write code that allows complex dependencies without having to bother with individual caches, and cached values do not need to be recomputed on each change, but only at some point. That point is at the latest next time the value is needed, but can also be done in the background so the user does not have to wait.
On top of this structure, is the CacheRegistry. The CacheRegistry is responsible for all cached objects. In GitLab, and indeed most CRUD/BREAD web-services, all objects have a (scoped) unique id. This means that if an issue belongs to both a project and a milestone, which indeed most of them will, there is no need to fetch the object twice from the remote. The relieves individual services from having to bother with fetching objects the most efficient way (and optionally dealing with complexities when multiple services depend on the same object): each service just requests the exact objects it needs to perform its computation and registers the appropriate relationships to get invalidated when the cache is. The CacheRegistry is also responsible for garbage collecting stale objects (objects without any (transitive) dependencies) and for refreshing the cache periodically.
It is the hope that by exploiting relationships between objects, it is possible to efficiently check them for freshness, and by explicitly tracking dependencies it is possible to efficiently recompute what is necessary. Using a few general concepts, it should hopefully be possible to decouple the business logic making use of the data, the data layer logic responsible for fetching the data, and the caching logic responsible for ensuring the data is up-to-date.
The initial version of the library is being written as part I Я Project Manager, but I want to use it more before I even think about publishing interfaces/making the library public.
To me, this seems like such an obvious general case and it surprises me, I could not find any library handling this already (though maybe my Google-fu is too limited). Maybe people are just accepting the bad trade-offs?
In any case, I’m curious if anybody else knows of a library that performs a similar function? Or has other use cases for such a library?

Looks like your use case goes a bit further than just caching as you seem to also try to calculate whether objects need to be fetched from remote. That seems quite specific so indeed perhaps understandable that this is not readily available.
The CacheRegistry, isn’t that just a fairly simple background process that invalidates cached objects based on the time that they were present?
The strategy for deciding when to invalidate data is the main part. I just think of it as a more sophisticated caching strategy, but I guess that’s more a matter of perspective. Thinking of it as a one-way optimistic replication mechanism is another valid perspective.
While not a real standard case, the method is applicable to anything that relies on a data model reachable using BREAD/CRUD/RESTful (web-)services, so I’d expect other application relying on a foreign data model to benefit. It is definitely non-standard that I need the entire foreign data model, but on the other hand this is basically JPA for web-services, which is why I thought/hoped there might be something similar out there. My guess is that other applications just limit their functionality to avoid excess remote access.
The CacheRegistry is responsible for object unification, so if I fetch the same foreign object twice, I only get the one local copy. Very similar to the JPA EntityManager. On top of that I have given it responsibilities to “keep the local objects fresh.” Currently, that means re-fetch objects when their TTL runs out (and invalidate dependents) and garbage collect objects no longer needed.
I don’t do live invalidation, though I probably should (for objects that should not be refreshed). Currently, invalidation is done on access, which obviously fails if an object with a longer TTL depends on one with a shorter TTL is accessed between the expiration of the one with the sorter and the one with the longer TTL, but this works if all objects are refreshed periodically.