
If that title doesn't give you like 2 or 3 lines in bullshit bingo, nothing except a meeting with a Scrum coach can help you there. It's accurate, though. It's a thing that should be extremely simple, yet either my Google-Fu is too weak or nobody else on the entirety of the internet and by extension, the world has done and documented that before, so I thought I'd act my part as a Nobel Peace Prize winner and document it.
I'll first introduce all the buzzwords from the title, and then get to what it all means (possibly restricted to the topics covered by the title). If you already know what at least Maven, Kubernetes
What Even is this All About?
CI/CD is the idea of building a pipeline that continuously builds, tests and deploys new code to the environment where it ends up running. CI/CD means continuous integration/continuous deployment and is a method for doing this automatically.

GitLab is an implementation of the git source versioning tool. Source versioning keeps track of changes so it is possible to have multiple versions of the same application concurrently and to revert changes that break functionality. Git is one such tool (others are Subversion or CVS), and GitLab is a popular integrated platform for self-hosted Git repositories. It provides features on top of "basic" code versioning, including wikis, issue trackers, and an expanding continuous integration component.
GitLab CI is a component of GitLab which allows continuous integration (and deployment of applications). Continuous integration means that every time anybody makes a change to a program, it is integrated with the remainder of the application and tested. The test typically comprises building (compiling) the whole shebang together and running the unit tests. Unit tests test individual components in isolation. More elaborate build pipelines also include integration tests, code quality analysis (e.g., using Sonar, PMD, FindBugs or the like), user interface tests (e.g., using Selenium, Serenity or for the real smart user, my own MBT Workbench) and perhaps deployment to test environments or even to production environments. GitLab CI is a tool for automating all of this; in GitLab CI, we configure build pipelines where individual steps like building, running unit tests, etc. together comprise the entire build pipeline. If any step fails, all subsequent steps are canceled (so, if, for example, the build fails, unit tests are not run, and if an integration test fails, the application is not deployed to the test environment). Put together, this ensures that developers do not have to bother with routine tasks like building and testing, while still ensuring the quality of the code that is put on production systems.

A really great thing about GitLab is that it is an integrated platform. The GitLab issue tracker may not be the best one out there, but it is integrated with the source repository, so it is possible to make simple links between issues and code commits, or between wiki pages and versions of the software. This means that it is easy to tie all the auxiliary information (tickets, documentation, etc) to the source code, and version everything together. This might not matter for a simple project, but it is not uncommon that I manage 3-5 concurrent versions of several projects at the same time (the version currently running on production and bugfixes, the next major version, perhaps another release in the future based on either the current production version on the next major version, and one or two concepts for possibly upcoming new versions). The real beauty of GitLab CI is that it is integrated with all of this.
Traditionally, you would have a build server managing your continuous integration (before continuous deployment really was a thing). A popular one is Jenkins (formerly Hudson). Aside from being a sketchy piece of garbage where you need too many plug-ins to accomplish anything meaningful breaking everything on most upgrades, a big problem of Jenkins is that the configuration is managed independently of your source code. That makes it inconvenient to manage multiple versions (each has to be set up independently) or to go back in time. GitLab CI solves this by keeping the configuration of the continuous integration with your source code. It is literally just another file stored together with your source code.
Most software developers rely on a build system of sorts. One of the classic ones
The particular build system to choose depends on the circumstances. I've used CMake for C++ development, and Ant and Maven for Java development. I've also heard nice things about Gradle. Here, I'll consider Maven because that's the one I'm most familiar with. Maven relies on binary versioned artifacts both for its own extension and for dependency management. Such artifacts can be a library you depend on (e.g., for handling web-services or as an integration platform) or it can be an executable module (e.g., to compile your code, to extract code quality metrics or to run unit tests). Artifacts can depend on other artifacts, and Maven ensures that when you depend on one module, all the modules required by the module are pulled in as well. This happens in a way so that if two modules depend on different versions of an artifact a version compatible with both is pulled in (in principle).

In Java development, a popular integration framework is

Spring Boot is a distribution of a lot of these technologies. It composes a lot of the frameworks under the Spring umbrella and ensures they work together. On top of this, Spring provides a powerful auto-configuration mechanism, which means that you very often just need to include a compatible library, and it will automatically be configured so it "just works" in most cases, and many adjustments to the configuration can be done centrally using a common configuration mechanism. In addition, it provides a lot of
In addition, Spring boot provides a

As a counter-reaction to larger and less practical traditional application containers,

Traditionally, applications ran on giant mainframes. This was out of necessity: an organization would only have a single mainframe, and you needed to run software using the central mainframe would beat running it on a toaster (but only slightly). This had the issues that malfunction of one application could impact other applications. Modern operating systems with memory protection helped, but it has still been best-practice to run each application on a separate machine. This improves isolation so malfunction or comprising one service will have more limited and easier-understood impact on other applications. Also, when this trend emerged, machines were often not powerful enough to run more than a single service. This isolation, unfortunately, means that a lot of hardware is necessary – each machine needs to be able to handle peak load. This means a lot of resources are wasted because

That lead to the invention of various lightweight virtualization techniques like chroot, Xen and Docker. Instead of emulating an entire computer with all components, operating systems would be aware they were not running on actual hardware but still see some level of isolation. If two applications cannot communicate via files or looking at one another's memory, does it really matter they run on the same machine? If they can have different versions of operating system libraries does it matter they don't have to physically handle (virtual) hard disks and memory? The answer is no. Paravirtualization is similar to what happened to application containers: instead of setting up a generic computer, highly specialized computers with minimal operating systems can be tailor-made to the application. Like paravirtualization, such computer images can even be combined with the application, making it possible to always run a particular application in a known environment where it is known to work. This is the idea of, for example, Docker images: they bundle the application (with optional microcontainer) together with a tailor-made stripped-down operating system which can be run in a limited virtualized environment. It is possible to make resource allocations (in particular memory/CPU/disk) and isolate each machine network-wise.
With paravirtualization making it so easy to set up new machines, it becomes viable to set up a lot of them. This has
Kubernetes virtualizes infrastructure. Individual applications are deployed across redundant clusters so the failure of any physical component will not cause the application to fail (assuming the application is written in a way to be able to handle this). Stronger still, Kubernetes is supported by many providers, most notably Google (Google Kubernetes Engine, GKE), Microsoft (Azure Container Service, AKS), RedHat (OpenShift), and soon Amazon (Elastic Container Service, EKS). It is also possible to host Kubernetes clusters yourself (though that is a royal PITA currently). That means it is possible to easily deploy entire application landscapes either in your own datacenter or at any of the major cloud providers. Solutions such as Minikube allow developers to also set up an entire infrastructure on their local laptop. All using the same infrastructure description.
That finally brings around to the start: if our application uses a microcontainer technology (like Spring Boot) and wraps everything into Docker images, we can deploy it to a Kubernetes cluster using a CI/CD solution. SWe can even deploy it to multiple different environments – setting up an environment just means deploying the same infrastructure to another cluster. Since Kubernetes allows us to use the same deployment descriptor, we can adhere to the traditional DTAP paradigm and deploy to a developer machine running Minicube for development, to a dynamically instantiated cloud environment using any of the cloud providers for running integration tests, to a permanent or semi-permanent cloud environment for acceptance testing, and to a self-hosted or cloud environment for production. That means we no longer have to make pretend environments for testing but can test on an environment identical to production rather than just very similar to. Since Kubernetes clusters allow automatic failover, we can even handle disaster recovery fairly simply by running our clusters in physically separate locations.

So, this is all unironically really, really good. The only thing missing is that I cannot be bothered to write the Docker and Kubernetes descriptions necessary to tie this all together. Luckily, I don't have to RedHat provides a service named fabric8, which provides a lot of the infrastructure tools in an integrated packet similar to how Spring Boot provides a lot of application tool in an integrated packet. We don't need to use the entire fabric8 infrastructure to benefit, though, and here I will only use the fabric8 Maven plugin. This plug-in automatically generates a Docker description using sane defaults and simple configuration for applications and can generate Kubernetes infrastructure descriptions from a combination of inspection and configuration. fabric8 can generate descriptions for generic Java applications, for Java web applications, and also has special configuration inspection for Spring Boot. By putting that in Maven, we can integrate that as part of our standard build process and CI/CD build pipeline. Which finally leads us to…
Show Me How it's Done!
Remarkedly, I could not find a good description of how to make all of this work together. It makes some measure of sense – fabric8 officially supports Jenkins (yuck!) rather than GitLab CI, and Kubernetes is still an emerging technology. Furthermore, Spring Boot 2.0 is still very new (came out a few weeks ago at the time of writing).

For this example, I'll use my Drunk Monkey Consulting application, a semi-joking application illustrating the Texas sharpshooter fallacy and survivorship bias. It was originally written as a relatively standard Spring MVC 4 application and deployed in a Wildfly container. I moved this to Spring Boot 2.0 to test the technology (I also use Spring Boot for my MBT Workbench, but that's a less interesting example here). The transformation was very simple despite also upgrading a couple of dependent components a major version, and I just have two outstanding points (the quotes widget at the right is not working for some reason and I'm currently using a transient in-memory database instead of the proper MySQL database).
The Drunk Monkey application has everything needed for a proof-of-concept: it has a bit of web-frontend, some database connectivity, uses a non-standard Spring component (Thymeleaf for styling) and Webjars for jQuery/Bootstrap and that sort of web 2.0 things.
As for GitLab and Kubernetes, I am running my own versions of both. That means I need to do a bit of configuration. I don't want a brute-force solution to setting up a build-pipeline, i.e., I want to pick up as much as possible using auto-configuration, and I want
Setting Up Docker Registry in GitLab
The Docker registry needs to be enabled globally in GitLab; make sure you have it enabled in your /etc/
[ruby]
registry_external_url 'https://registry.westergaard.eu'
registry['enable'] = true
gitlab_rails['registry_path'] = '/home/registry'
[/ruby]Make sure that the external URL points towards your GitLab install. I'm going via a central reverse proxy but the details are less relevant here.
Make sure that Pipelines and Container registry are both enabled under Settings / General / Permissions:
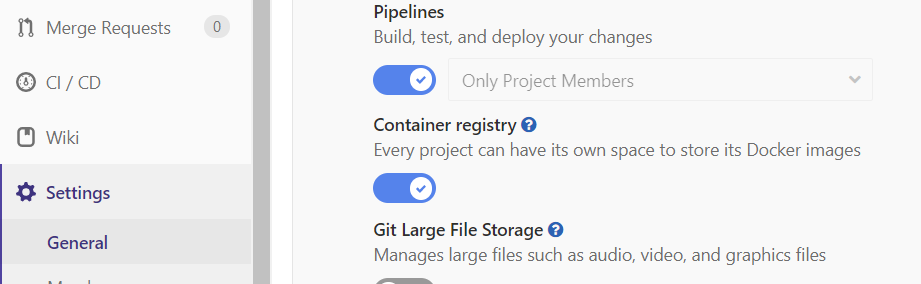
With Container registry enabled, we get an entry to store Docker images, and when running a GitLab CI pipeline, we get a handful of variables identifying the registry and credentials (the ones starting with CI_REGISTRY).
Setting Up Kubernetes in GitLab
Setting up a Kubernetes cluster is out of
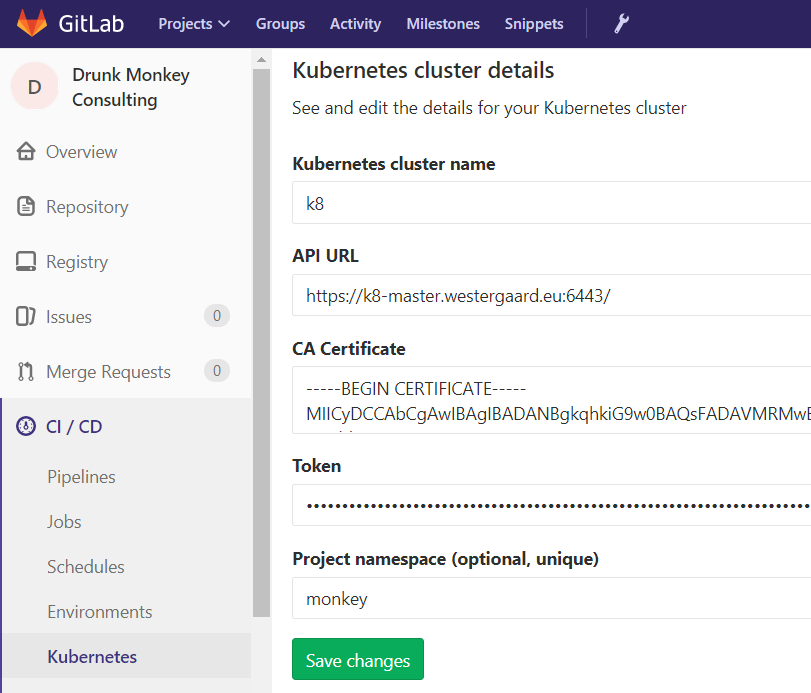
With this, we get a bunch more variables in GitLab CI for tasks that are tied to an environment. These provide connection details for the Kubernetes cluster and credentials.
Note that GitLab currently doesn't really support RBAC security and this
Setting Up Fabric8 Maven Plug-in
I want this to be as simple as possible. Fabric8 knows about Spring Boot and I don't want to bother with configuring anything it can do automatically. This includes not setting up any credentials or the like.
Luckily, my solution ended up with the simplest possible configuration in pom.xml:
[xml]
<build>
<plugins>
<plugin>
<groupId>io.fabric8</groupId>
<artifactId>fabric8-maven-plugin</artifactId>
<version>3.5.38</version>
</plugin>
...
</plugins>
...
</build>
[/xml]I just use the latest version and don't configure anything in my pom.xml. I also don't bind any targets to any build phases, so during
Currently, the application is so simple I just manually invoke the jar file for testing, but I'm certain that since I have no configuration, I could use it to deploy directly to Minikube with little or no extra configuration.
Spring Boot Configuration
Fabric8 assumes that Spring Boot applications use the Metrics functionality. I had that configured anyway, but if your application doesn't, you need to configure that. The easiest is to add a dependency on the metrics Spring Boot starter:
[xml]
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
...
</dependencies>
[/xml](I'm using the Spring Boot BOM to manage versions and don't need to specify the version above.)
Like everything Spring Boot, I have configured my usage of Metrics in my application.properties. This can also be done using any of the other configuration
[ini]
management.security.enabled=false
management.endpoints.web.base-path=/
management.server.port=8081
management.port=8081
management.endpoints.web.exposure.include=*
[/ini]I disable any sort of security because my application doesn't need it. We should not expose the metrics to the internet, so I also move the management server to a separate port, 8081 (the main application port is 8080). I need to set this property twice; the property changes names from Spring Boot 1 to Spring Boot 2, and the management.server.port is used by Spring Boot itself, while fabric8 still relies on the older management.port property (this has been fixed in the upcoming version 3.5.39 version of the plugin). We also relocate the service; in Spring Boot 2, the default context path is /actuator but there's no need for that in this case, so I relocate it to /. Like the port, we also need a Spring Boot 1 version of this if we relocate it to anything other than the root (as is default in Spring Boot 1). The property in Spring Boot 1 is called management.context–path. Finally, I enable all Metrics endpoints. I don't believe this is necessary, but I have other plans for this as well.
GitLab CI Configuration
The last part is the actual set-up of GitLab CI. I am running GitLab CI using OS runners without Docker currently, though that may change.
The first part of the .gitlab-ci.yml is pretty standard:
[generic]
stages:
- test
- build
- package
- deploy
- staging
- production
unit_test:
stage: test
script:
- mvn clean test -U -B
.build: &build_template
stage: build
script:
- mvn package -U -B
tags:
- java8
except:
- tags
master_build:
<<: *build_template
only:
- master
- tags
artifacts:
expire_in: 1 month
paths:
- target/*.jar
- target/classes/application.properties
[/generic]We set up a simple 6 stage build pipeline. The test stage builds the project and runs the unit tests. The build stage is implemented using a task that packages up the project. It defines project artifacts, in
[generic]
build_image:
stage: package
only:
- master
- tags
script:
- mvn fabric8:resource fabric8:build fabric8:push \
-Ddocker.host=tcp://docker-manager.westergaard.eu:2375 \
-Dfabric8.generator.from=fabric8/java-alpine-openjdk8-jre \
-Ddocker.registry=$CI_REGISTRY i\
-Ddocker.username=$CI_REGISTRY_USER \
-Ddocker.password=$CI_REGISTRY_PASSWORD \
-Dfabric8.generator.registry=$CI_REGISTRY
- "echo -ne ' imagePullSecrets:\\n - name: gitlab-registry\\n' \
>> target/classes/META-INF/fabric8/kubernetes.yml"
tags:
- java8
environment:
name: package
artifacts:
expire_in: 1 month
paths:
- target/classes/META-INF/fabric8
[/generic]Some lines have been split up for readability (ha!), but need to be on one line so GitLab CI doesn't shit itself over incorrect whitespace in YAML.
We rely on the 3 fabric8 targets: resource, build and push. They need to be executed together to ensure that the resources (describing the Kubernetes deployment) have the same identifier as the pushed image.
We need to specify a Docker host. I am using a different Docker server from my Kubernetes cluster. This is specified because I'm not running Docker on my build machine. I could probably get rid of this if I did or if I were using a Docker runner.
I specify a custom Docker base image which is based on a very tiny Linux distribution and only includes the JRE (instead of the full JDK as the default image). This reduces the resulting image from ~200 Mb to around ~100 Mb.
I then specify the Docker registry (4 lines). The first 3 lines should be obvious; I specify the location and credentials as set automatically by the CI server. The extra inclusion of the registry tells the resource generator to tell Kubernetes to (later) pull the image from the private Docker repository.
I then perform a hot-patch to one fo the generated files. The Docker repository offered by GitLab is authenticated, so I need to tell Kubernetes how to authenticate itself but as far as I could see, there's no way to configure that without making my own deployment descriptor from scratch. This is not optimal but works for now. Notice that the number of spaces has been abbreviated here and need to match what is already in the generated
I actually provide a (fictional) environment to this stage though none should be needed. This is to ensure that the Kubernetes cluster is passed by the CI environment. Fabric8 tries to contact the cluster to auto-detect type and version. If we don't provide it, it will rely on defaults and yield warnings. This only works if the environments are identical (or at least similar enough to be compatible). I might be able to use the Kubernetes cluster for the image build instead of a separate Docker host, but I did not look into that as I happened to have a Docker server which sees little use otherwise anyway.
We register the generated resources as artifacts. These are used for deployment:
[generic]
staging:
stage: staging
script:
- kubectl create secret -n $KUBE_NAMESPACE \
docker-registry gitlab-registry \
--docker-server="$CI_REGISTRY" \
--docker-username="$CI_REGISTRY_USER" \
--docker-password="$CI_REGISTRY_PASSWORD" \
--docker-email="$GITLAB_USER_EMAIL" \
-o yaml --dry-run | \
kubectl replace -n $KUBE_NAMESPACE --force -f -
- mvn fabric8:apply
- sleep 20
tags:
- java8
environment:
name: staging
url: https://$CI_PROJECT_PATH_SLUG-$CI_ENVIRONMENT_SLUG.westergaard.eu
[/generic]The first part of the deployment includes storing a secret in Kubernetes. The secret is generated from the time-limited token generated for the CI runner and used by Kubernetes to fetch Docker images from the GitLab Docker registry. This password is only available while the CI job is running, so if Kubernetes cannot authenticate and fetch the Docker images before the CI job is complete, it will not be able to. Alternatively, you can generate a user token for Kubernetes and use that to authenticate against the registry and either store that manually or use a GitLab secret variable to store it.
The remainder is fairly standard: we apply the Kubernetes configuration and then wait for 20 seconds. The delay is there to make the CI job jun a little longer to giver Kubernetes more time to start fetching the newly generated Docker image.

Still Missing
I'm currently relying on an h2 database. I want to also move that to my regular MySQL server and provide the credentials using GitLab secret variables for each environment. It would also be neat to try deploying a fresh MySQL Docker image to Kubernetes and connect the main application to that.
GitLab supports Ingress for exposing services more or less automatically. I would like to expose the application automatically on the URL instead of, as currently, manually exposing it via my regular reverse proxy and the ClusterIP.
I also want to make use of the Prometheus instance GitLab offers to install (though it fails right now). Spring Boot Metrics already exports data in a Prometheus-friendly format and even if it didn't, the Java image used by fabric8 supports exposing JMX to Prometheus and Metrics also exports data to JMX, so it should be possible with just a few magical incantations to get almost automatic application monitoring and tracking directly in GitLab. That would
Finally, I want to make use of multiple environments. I use the free version of GitLab, so I can only configure one Kubernetes cluster per project and cannot pin it to a particular environment. That's probably ok, but I would like to also be able to publish my applications to a separate namespace and expose another service. It seems like this would be relatively simple.

Yeah, thats really great writing! You made me lough, thanks!
Also technically very interesting and close to my use case, migrating a JavaEE webapp with simple servlets to gitlab auto devops.
I think fabric8 is the key to success here. Any further results from your side?
Thanks for the kind words 🙂
I’ve not tried setting up a JavaEE application using this pipeline yet (though I just took over an application, where I’ll likely do something of the sort). Fabric8 does have a generator for “old-fashioned” web-apps and even comes with a couple of images for application servers (Wildfly, Tomcat, Jetty), so if you use one of those, my guess is it is easy to get going).
Gitlab auto devops is a bit different; it tries doing your CI/CD automatically. I have not played much with it because when I started looking into it, it was far from sufficiently mature. Now, it has improved significantly, but I’ve already developed this pipeline which works for us (and also works with our process directly as it was developed with that in mind).
Since I originally wrote this, GitLab has improved support, so some of the hacks I had to resort to are no longer necessary; for example, you can now use inclusion (to keep your CI/CD in a separate project). I wrote a longer series on setting up an entire CI/CD pipeline starting here which is a bit newer, but I have subsequently moved from GCloud to AWS (don’t do that, GCloud is nicer for k8s).
Hi Michael,
Were you able to configure fabric8 to speak to multiply kubernetes cluster at once.?
Or did you had to use kubectl to change cluster context.
Kind Regards,
Joseph
Hi Joseph,
Kind-of. It’s a bit of a hack, but works great for a production system for a customer. Basically, what I do is that I set up a second project which is connected to the production system. The second project is empty except for a tiny bit of GitLab CI code. The primary project then prepares the build and deploys to test systems.
When I click release to acceptance/production, it uses GitLab triggers to launch a build of the other project with a parameter including the primary project id.
The deployment project then fetches the original project artifacts and deploys them to its own cluster, the acceptance/production cluster. It does so using kubectl because that way it doesn’t need the entire project configuration to run fabric8, and fabric8 has already generated the k8s during the release phase anyway so it adds very little over plain kubectl.
Even then, with the free GitLab, you need to manage credentials manually; paid versions allows cross-project dependencies and triggers, while the free version requires a dummy user to trigger the foreign pipeline and to fetch the artifacts.
It is not optimal nor really elegant, but at least it works. GitLab has much better support for namespaces (each environment gets its own namespace now; it didn’t when I wrote the original post), so you can in principle just use the same cluster and do resource control on namespace level.
Regards,
Michael