Micro-services is the buzzword-compliant way to talk about applications these days. That’s also ok. It’s not great, but it’s ok. Micro-services have two problems in my opinion: they are too small, and they are not small enough. To solve all your problems, even that weird one you are too shy to tell your doctor about, we instead propose to switch to micro-applications.
Micro-services are too small for many purposes, leading to applications becoming 736-piece all-black jigsaw puzzles worth of fun for the ops team to deploy. simultaneously, the micro-service paradigm does not take user-interfaces into account, so on top of your impossible to maintain micro-services jigsaw, you dump a huge turd of a monolithic user interface and pretend to be agile.
There are, of course, proposed solutions to this, one of which is (and this shouldn’t be surprising) micro-frontends. It’s a tantalising idea: group your application around features and include frontends in the grouping. It still gives you a big ol’ all-black jigsaw, but at least nobody shit on it. I’m curious what this idea brings once it matures a bit, but as of right now, it is not really supported by frameworks and it seems super-complicated at this stage. Micro-frontends also don’t really deal with the big problem of micro-services: they are small, and to make a working application, you need to assemble it out of many components, that all need to be in versions that are compatible.
A very important point of architectural patterns is that they have advantages and disadvantages. Micro-services are good for splitting applications into smaller parts that can de deployed and upgraded independently. Which if put on a Powerpoint is sufficient to convince people to go ahead in most cases. The big disadvantage is fragmentation and versioning hell. In some situations the advantages outweigh the disadvantages, and in some not. For example, if your application is already relatively simple, then why bother with micro-services in the first place? If all you have is a few thousand lines of code, splitting them up is not going to accomplish much. Rather, it will be problematic when you get back to the application after a while, because now you have to trace a feature up between 3 different micro services in separate projects to understand and update a feature.
I posit that most applications are small. Sure, there are big ones like Facebook or Amazon, but let’s just rid ourselves of our availability bias and admit that most applications solve a relatively simple task. Case in point, this week I have worked on 9 versions of 7 applications for 4 different customers, and it’s only Wednesday. I definitely see more applications rather than large applications, so I prioritise being able to trace a feature from the UI all the way down to the database without having to go thru 15 different micro-services. That’s not true for everybody, and this maybe doesn’t apply to you if you are working for Google or Ebay, though to be honest, it probably does. And if you’re building the next big application, it definitely applies to you (just like you should use a grown-up database instead of some noSQL shit out of a misunderstood “we need to able to scale in the future” concern – prepare for 1000 users before you prepare for 1000000).
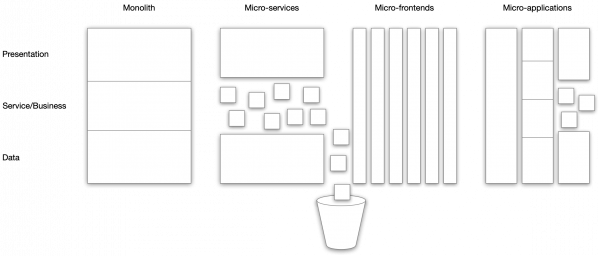
Which brings us to micro-applications. Build functionality as “monolithic” micro-applications that are completely self-contained: they contain the business logic, view logic, and user-interface all in a neat self-contained package. A micro-application deals with everything necessary for it to work, and contains no hidden dependencies (if it needs a database it has its own that is not shared with other applications, for example). All external dependencies are documented as formally documented web-services or using a publish-subscribe queuing system using strongly typed messages.
This means that most dependencies are internal and easy to trace. The few external dependencies are clearly marked and documented in a manner that a computer can check. Most importantly, the services necessary to tie the user-interface to the application are not viewed as external services, but as internal ones. They are easy to trace within the application, and easy to change. They can be changed because they are internal and we don’t have to consider what the ripple effects of changing a service to get a list of customers, because we know: it only changes the single user-interface that is already a part of the application.
Micro-applications also allow us to make the internal application slices as we like. Some benefit from a standard three-layer architecture, some have no UI. Some have no persistence. Some may need a bonus data virtualisation layer. Some may benefit from a classical application server architecture, some may benefit from a queue or ESB-driven architecture, some are current modern fat binaries comprising everything needed to run the application, while some may be run in a serverless environment. Some need a lot of memory, some a lot of slow disk, some one large CPU, some a lot of CPUs, some very fast disk, and some a lot of powerful GPUs. Instead of having to impose the same structure on all applications, we can make the structure that is most suitable for each micro-application. Each micro-application can not only be developed by different teams or departments within the same company, but even be out-sourced to different companies. Micro-services also have many of these advantages. Also, very importantly, while it is certainly possible to make each micro-application using its own frameworks and architectual style, there is also value in uniformity, and while it may be more efficient (let’s be honest, what the developer really means when saying that is “fun”) to use slightly different architectures, maintenance as a whole is probably a lot cheaper if similar applications share architecture, even if that may be sub-optiomal for each individual application.
To the end-user, there is no need that a set of micro-applications should be thought of as multiple applications. When you’re using Google services, you do not think of Gmail and Google Docs are separate; you can switch effortless (as effortless and something coming out of the UI-wasteland that is Google) between them and don’t have to log in multiple times. They have a reasonably similar look and feel. This is facilitated by sharing the same layout and using a functional Single Sign-on service that effortlessly logs you in to services when needed.
Security also becomes simpler. A micro-application is responsible for securing its own data. The data is 100% controlled by the application, so it only needs to concern itself with what it does. The only external interfaces are documented and need to be treated as part of the application. If an application needs data from another micro-application, it obtains it via a web-service. The web-service is secured using the same SSO tokens as everything else in the application, so the application does not have full access to foreign data, only by what is grated by the user token.
Micro-applications should be split up so logically connected functionality and data is grouped together to that external interfaces are minimised and functionality that is needed/updated together, is maintained and lives together. Maybe the users are (almost) disjoint (pages for customers, suppliers, and employees, for example), maybe they deal with data owned by (mostly) disjoint departments (product catalogue, customer databases, and financial data, for example). Sometimes, data is instead split by domain; for example, a web store can be split into product browsing, shopping cart, product catalogue maintenance, and customer data maintenance. The responsibility of each micro-application is then to maintain and secure the data it owns, and to expose it using simple and clear web-services to other micro-applications.
Proponents of micro-services may say that keeping services internal makes it hard for other applications to re-use them. There is virtually no truth to that. Exposing a service is not a technically challenging task. Documenting and securing such an interface is. Either the micro-service proponent is just exposing services with little thought to stable and secure interfaces, or they spend way too much time and money documenting and securing interfaces that are only ever used by a single application. I would argue that micro-services are less agile than micro-applications: if micro-services are well-documented, changing them is complex because all consumers need to be updated. In micro-applications, internal services can be changes without changing documentation or notifying consumers, because we know there are none. If micro-services are not documented, changing them is a game of Russian roulette combined with a treasure hunt: you have to go look for all services relying on the service you wish to change and hope that none of them rely on an undocumented peculiarity. Micro-applications have a clear distinction between externally usable services and internal services. Internal services (most of them) can be changed risk-free without a big hunt for users, as the users are all in the same application. External services are few and changed rarely, but always documented and traceable. Relying on external data should be a big deal, and the challenge is not technically writing the web-service.
Micro-applications are not the answer if you need information from wildly different domains on the same screen. Micro-frontends claim they can solve that problem, and maybe they can, but if you are developing serious applications you re probably better off with a monolith or some micro-service abomination (which is also a monolith in the user-interface). In such cases, you can stretch the definition of micro-application (which I’ve never properly defined anyway) to multi-application and make either a monolithic or micro-service-based application for the web-shop, a backend application which can probably be largely monolithic while relying on some services shared with the customer-facing application, all feeding financial data into an off-the-shelf financial package. Large applications like Facebook likely have some homebrew bastardized version of micro-frontends, or are actually some notion of micro-applications (this is very obvious if you have used, e.g., Amazon web-services, where each service clearly has its own team making the UI and APIs).
Micro-applications is not some theoretical untried framework. The main micro-application architecture I use is as I’ve described in previous blog posts (part 1, part 2, part 3 coming Real Soon Now). This architecture uses Spring Boot for the service layer and Angular for the Presentation layer. The architecture encourages sharing GUI components to achieve a uniform look and feel between micro-applications and relies fundamentally on Keycloak for SSO. I’ve also written about that, and the as-yet unwritten part 3 of the Spring Boot/Angular architecture will go into more detail.
This architecture has been rolled out to multiple customers. At one customer, we have a good handful of micro-applications (the number changes as we add or retire applications). They are now relatively uniform, though we just went thru a multi-year migration to the above architecture. It was a multi-year endeavour not because it had to be, but because we could take our time and migrate applications individually. Applications are similar, but some are almost 100% run on the frontend while others have no frontend at all. In addition to the Spring Boot/Angular applications, we also employ Keycloak with custom theming to match with the custom applications. Keycloak is a classical Java Enterprise application running in Wildfly with a AngularJS frontend. The landscape also includes a CMS maintained by a third party. The look and feel also matches the applications. Some applications rely on a MySQL database for storage, others on PostgreSQL, and some have no data dependencies. One application is just a couple of shell scripts in a Docker container deployed decentrally at clients of the customer. but most important, once a user is using any of the applications, they can navigate to others without ever knowing that is what they are doing. Some require authentication while others do not. Once authenticated, users can access applications they have rights to, and they will only be asked to authenticate when they reach the first application that requires it.
So, in conclusion, micro-applications allow balancing the need for splitting applications up for the many good reasons that makes sense, with the need for keeping IT landscapes simple. They do that by grouping like functionality together to minimise external interfaces and reduce the number of components that need to be touched to make a change. Micro-applications allow applications to use their own technologies and architectures, but recommends uniformity over small local improvements. Micro-applications are larger than micro-services and keep connections between layers internal so they can easily be changed, while keeping external interfaces stable. Micro-applications are largely self-contained and easy to deploy. At the same time, they are also easy to test, as they have few and well-documented external dependencies that can easily be stubbed using common tools. To the end-user, a micro-application landscape presents as a single application.
