It’s been a while; aside from a single vaguely formulated post about how I was refactoring the MBT Workbench, I have not really posted anything substantial since September last year. Coincidentally, this matches up with the approximate time when the “semester” began and I got most of my mental excess tied up in studying. Now, the exams are over, and I start getting back on working on model-based testing. In this post, I outline some loose ideas I have for improving what is already in the MBT Workbench. These features do not attempt to broaden the scope of the tool to new domains, but instead to pull in more cool methods from academia to aid in test-driven development and business-driven development.
The concepts, I want to go thru are process mining and archetypes ((If you didn’t notice, I’d like to stress how this ties neatly back to the title of the post and also signals not only what the remainder of this paragraph is about but really outlines the entire remainder of this post. Because, that’s a thing I’ve been focusing on, like a lot, during my studies recently.)). The first should aid in deriving and simplifying models. Used iteratively, it is intended to improve testing for very complex systems where a naive exhaustive approach is simply impossible. The last is an attempt at using what we already know about common ways to structure applications, to elevate the testing from single web-service/-page interactions, to also handle and support multi-service/-page interactions.
Process Mining
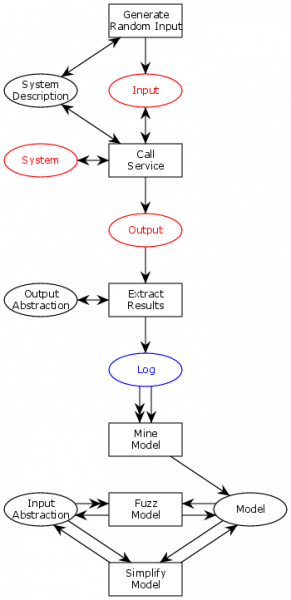
Process Mining is a technique for creating/augmenting models from system executions (logs). It is also coincidentally invented here in Eindhoven and I spent a couple of years working with the people who originally invented the method. The process mining approach is often summarized as the below three relationships between logs and models:
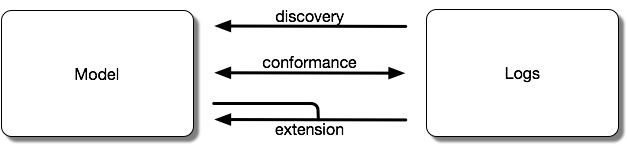
When we derive a model from a log, this is called discovery. When we check a log against a model, this is called conformance checking. This is very similar to the testing we do here, except we compare the model against the actual system (by executing the system systematically and generating a “complete” log in a certain sense). Finally, it is possible to use the model and log together to derive a better model.
I have updated the generic meta-model for the MBT Workbench below, with process mining added at the bottom right.
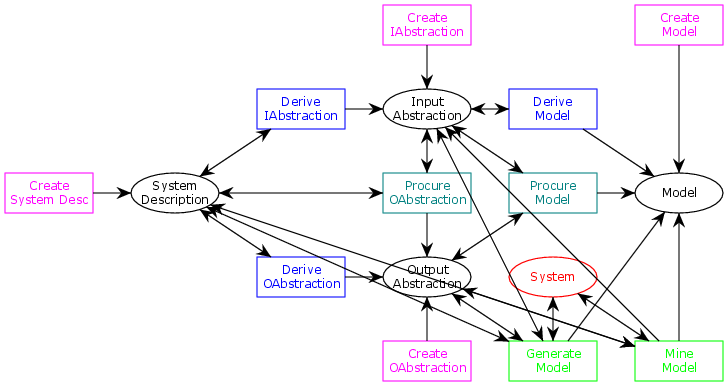
There’s a smidgen too many arrows for the model to remain readable, so here’s a simplified model that focuses on process mining, and the few other actions necessary to support it:
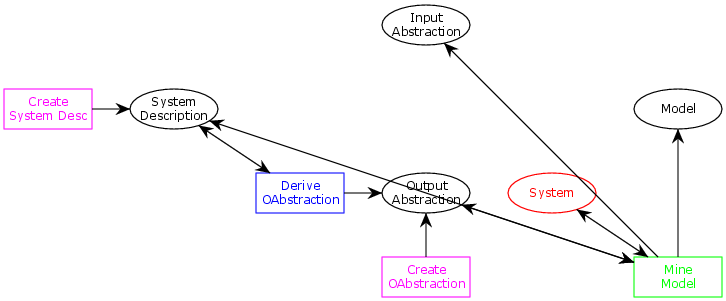
Now, the idea is that given a system, a description of the system (like a WSDL description of a web-service), a way to interpret the output of the system (the output abstraction), we can automatically generate the input abstraction and model.
The idea is as follows: using the system description, generate random input to the system and send it to the system. Then use the output abstraction to transform the results of the actual system into something we can interpret in the model space. By repeating this, essentially, performing a random walk of the system, we basically derive a log from the system. I might augment the meta-model with logs as a first-order component to split this procedure up and to allow derivation of logs in different ways, but for now, the simplified view suffices. This is summarized in the below figure illustrating the process, similar to how I previously illustrated the entirety of model-based testing:
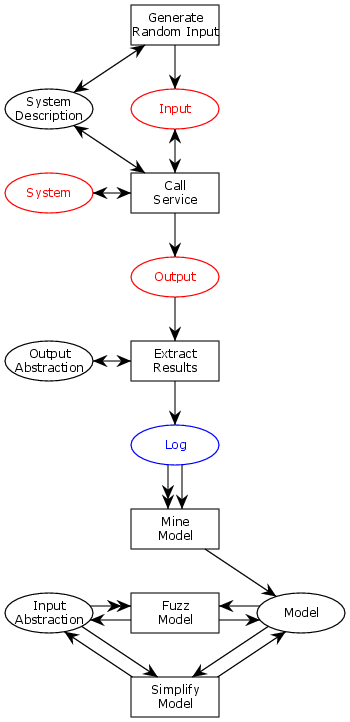
We see how we generate random inputs based on the system description and use these to call the service. This results in outputs, which we extract using the output abstraction. We then invoke the process mining discovery algorithm on this resulting log to obtain a model. People familiar with Petri nets will notice that as soon as there are tokens on the system description and system places, the generate random input transition can fire as many times as we want, producing an unbounded number of tokens on the input place. Each of these corresponds to a random execution. Similarly, the mine model transition has an extra weird arc; this is a reset arc, which means we consume all the tokens (the entire execution log) for the process mining algorithm.

After this, we go into a loop of improving the generated model; this is very similar to the extension part of process mining, but using pre-existing concepts in the MBT Workbench. First, we apply fuzzing to the resulting model. The fuzzing algorithm tries to check whether the borders between equivalence classes discovered are accurate, complete, and minimal by intelligently making even more executions of the model. Since the original input was entirely random, there’s a good chance that the borders discovered were largely garbage, this step is expected to make vast improvements to the resulting model. My original fuzzing work was based on the ideas of Microsoft’s gray box fuzzing, which does some inspection of applications to ensure that optimal fuzzing is achieved. I believe that the combined approach using process mining and fuzzing achieves many of the same advantages without having to even instrument the application, thereby making the approach independent of the
Fuzzing has a tendency to wildly blow up the complexity of the model, so after that, we apply a model simplification step as previously explained. This step gets rid of unwanted variables and leaves us with a model that is minimal. Again, there is no limit on how many times we can execute the fuzzing and simplification steps, so if needed, we can perform them repeatedly to improve models.

Archetypes
A lot of my work for the MBT Workbench assumes that services are idempotent or even functional, so it makes no difference if we execute services 1, 2 or more times. We should always expect the same result, at least after executing them a couple of times.
This certainly holds for a significant set of services: all lookup-style services, validation services, etc., but not for all. Especially not once we start taking service interactions into account. In my most recent post, I started outlining the work I want to do in exactly this direction to support more advanced service interactions and web-page testing.
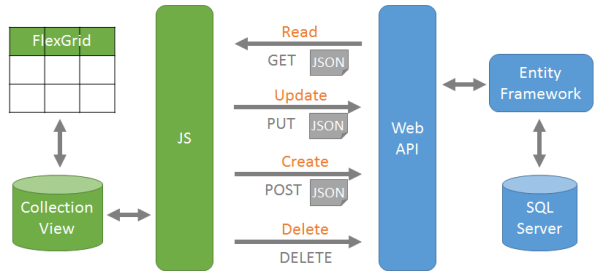
To properly guide the tool in such a setting, we would need some sort of composition language and a way to describe interactions. To avoid the MBT Workbench becoming a mess like most other testing tools, where the user is expected to state the obvious, I want the tool to take a very opinionated approach to such interactions, and the way I want to do that is by assuming that services can be categorized into CRUD operations/RESTful web-services. We, therefore, assign an archetype to each web-service or web-page, corresponding to one of the CRUD (create, read, update, delete) operations.
This provides the MBT Workbench with information about assumptions it can reasonably make about the individual service (create, delete and update operations are idempotent and read operations are functional) and about service interactions (create and delete operations are inverse, update operations have another update operation as their inverse).
It also allows us to make interaction schemata (test a create operation by following up with a read operation and clean up with a delete operation). The application would come with predefined schemata but also allow users to define their own. Such a schema can be applied to any set of CRUD operations for each model object.
Speaking of model objects; these could be represented in the application as well. They could be read from XML schemas (we already read XML schemas as part of the WSDL web-service descriptions), some UML format, or by inspecting code or database schemas directly. This information could then be used to share input/output abstractions between CRUD services/pages for each model object
Minor Optimizations
I am also considering a fast-test option, that allows the testing module to only run the test for certain parts of the model; for example, just running a test for a single value in each execution trace equivalence class instead of once for each combination of input variables. This will be useful for performing fast complete test runs without having to go thru the entire Cartesian product with a slight loss in reliability of the results (assuming that nightly or weekly test runs will run the full procedure), but will also allow testing when the full combination of possibilities is infeasible.
I am also considering a simple partitioning algorithm to augment my existing model simplification algorithm. The simplification algorithm gets rid of variables that can be entirely predicted by a set of other variables, and are therefore unnecessary for the test. The partitioning algorithm instead splits up tests that contain variables that independently influence the test results. Going with our original insurance example (car insurances are granted but not to men under 25), if we also include a third variable, “hat,” indicating the type of hat the applicant wears. Applicants wearing no hat are judged based on the previous algorithm, while applicants wearing baseball caps in reverse are never granted insurance (they are no-good hicks who will crash their car at their first convenience) and applicants wearing a fancy hat are always granted insurance (because they must be rich). Now, the hat variable (when present) means that the values of the other variables do not matter at all, so testing it together with the others will just cause the space to unnecessarily grow from 3 * 2 + 2 = 8 to 3 * 2 * 3 = 18, assuming we have 3 values for age (below 25, 25, and above 25), 2 for gender (male and female), and two/three values for hat (reversed baseball cap, fancy hat, no hat).
Conclusion
So, this is where it ends today. We have looked at suggested ways to improve model generation in the MBT Workbench using process mining techniques and how to facilitate service interactions using archetypes based on the CRUD operations. We also saw a couple of minor optimizations that didn’t naturally fit into either category.
I need to get back up to speed on MBT Workbench development. I have done a couple of breaking changes and want to eliminate the last ones, so I once again have a stable basis on which to work where I don’t need to worry about stupid technical details. I will then probably look into the whole process mining approach first; I think a very simple algorithm should suffice for now (after all, I am only considering single service interactions for now, so logs will be very short). Then I’ll probably look into service interactions, looking at archetypes and web-page testing at the same time.
